What is batch processing
Batch processing refers to the way execution environments process batches of data handled by a component using a grouping mechanism.
By default, the execution environment of a component automatically decides how to process groups of records and estimates an optimal group size depending on the system capacity. With this default behavior, the size of each group could sometimes be optimized for the system to handle the load more effectively or to match business requirements.
For example, real-time or near real-time processing needs often imply processing smaller batches of data, but more often. On the other hand, a one-time processing without business contraints is more effectively handled with a batch size based on the system capacity.
Final users of a component developed with the Talend Component Kit that integrates the batch processing logic described in this document can override this automatic size. To do that, a maxBatchSize option is available in the component settings and allows to set the maximum size of each group of data to process.
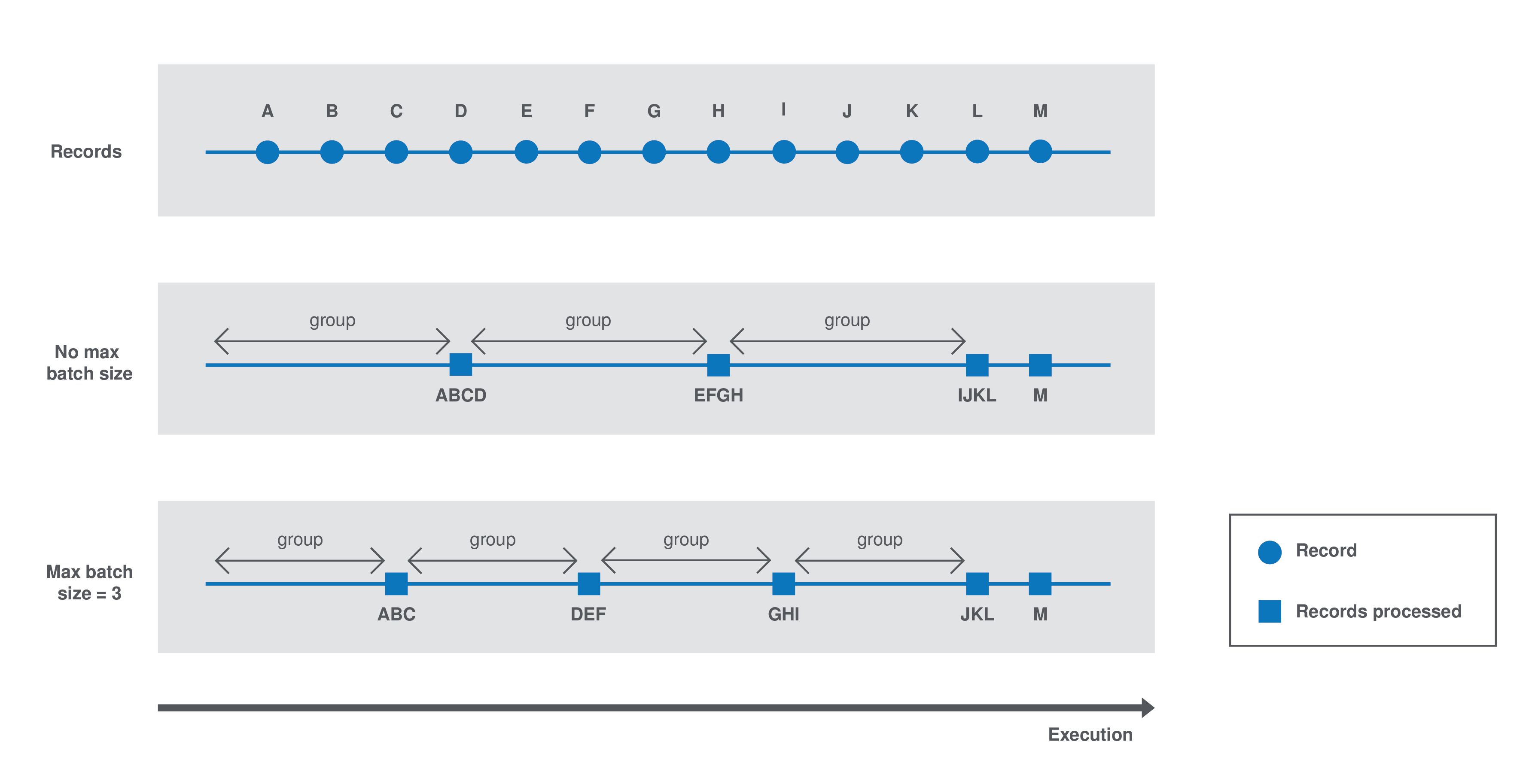
A component processes batch data as follows:
-
Case 1 - No
maxBatchSizeis specified in the component configuration. The execution environment estimates a group size of 4. Records are processed by groups of 4. -
Case 2 - The runtime estimates a group size of 4 but a
maxBatchSizeof 3 is specified in the component configuration. The system adapts the group size to 3. Records are processed by groups of 3.
Batch processing implementation logic
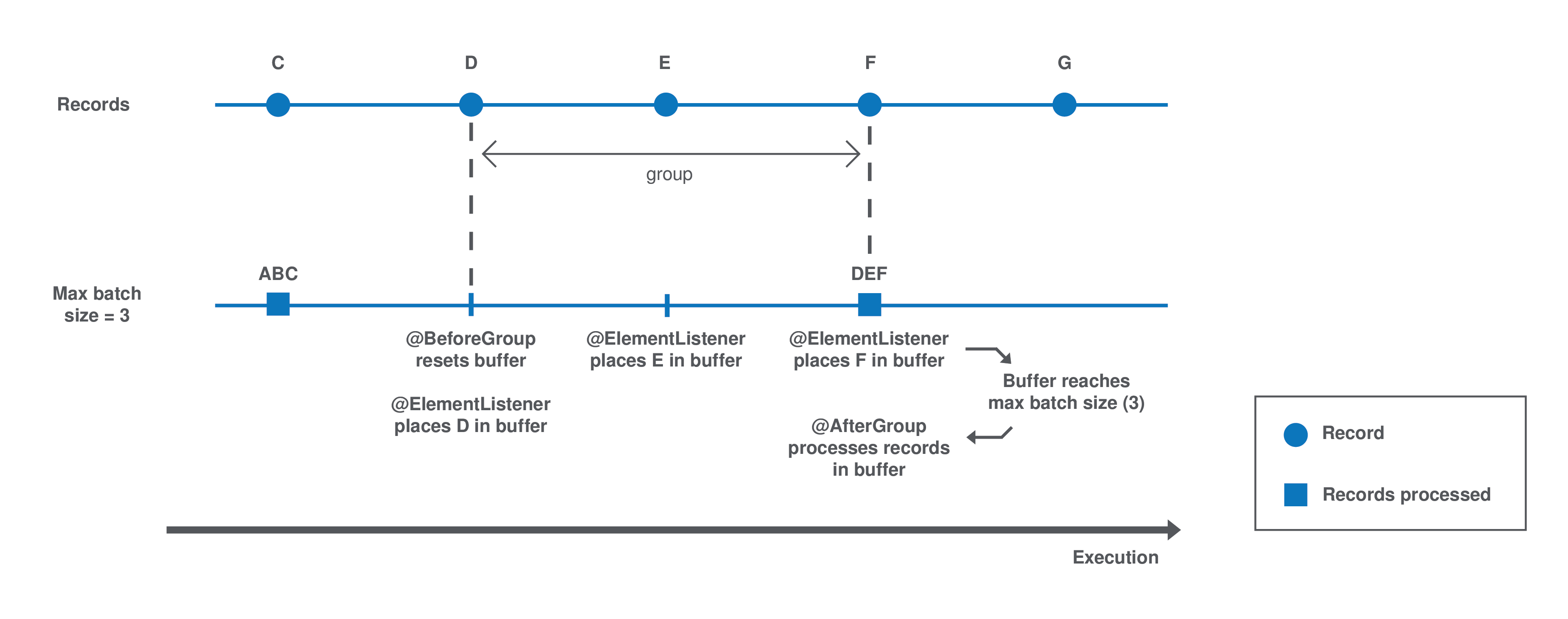
Batch processing relies on the sequence of three methods: @BeforeGroup, @ElementListener, @AfterGroup, that you can customize to your needs as a component Developer.
| The group size automatic estimation logic is automatically implemented when a component is deployed to a Talend application. |
Each group is processed as follows until there is no record left:
-
The
@BeforeGroupmethod resets a record buffer at the beginning of each group. -
The records of the group are assessed one by one and placed in the buffer as follows: The
@ElementListenermethod tests if the buffer size is greater or equal to the definedmaxBatchSize. If it is, the records are processed. If not, then the current record is buffered. -
The previous step happens for all records of the group. Then the
@AfterGroupmethod tests if the buffer is empty.
You can define the following logic in the processor configuration:
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Collection;
import javax.json.JsonObject;
import org.talend.sdk.component.api.processor.AfterGroup;
import org.talend.sdk.component.api.processor.BeforeGroup;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.processor.Processor;
@Processor(name = "BulkOutputDemo")
public class BulkProcessor implements Serializable {
private Collection<JsonObject> buffer;
@BeforeGroup
public void begin() {
buffer = new ArrayList<>();
}
@ElementListener
public void bufferize(final JsonObject object) {
buffer.add(object);
}
@AfterGroup
public void commit() {
// saves buffered records at once (bulk)
}
}You can also use the condensed syntax for this kind of processor:
@Processor(name = "BulkOutputDemo")
public class BulkProcessor implements Serializable {
@AfterGroup
public void commit(final Collection<Record> records) {
// saves records
}
}
When writing tests for components, you can force the maxBatchSize parameter value by setting it with the following syntax: <configuration prefix>.$maxBatchSize=10.
|
You can learn more about processors in this document.