What is a processor
A Processor is a component that converts incoming data to a different model.
A processor must have a method decorated with @ElementListener taking an incoming data and returning the processed data:
@ElementListener
public MyNewData map(final MyData data) {
return ...;
}Processors must be Serializable because they are distributed components.
If you just need to access data on a map-based ruleset, you can use Record or JsonObject as parameter type.
From there, Talend Component Kit wraps the data to allow you to access it as a map. The parameter type is not enforced.
This means that if you know that you will get a SuperCustomDto bean, then you can use it as parameter type. But for generic components that are reusable in any chain, it is highly encouraged to use Record until you have an evaluation language-based processor that has its own way to access components.
For example:
@ElementListener
public MyNewData map(final Record incomingData) {
String name = incomingData.getString("name");
int name = incomingData.getInt("age");
return ...;
}
// equivalent to (using POJO subclassing)
public class Person {
private String age;
private int age;
// getters/setters
}
@ElementListener
public MyNewData map(final Person person) {
String name = person.getName();
int age = person.getAge();
return ...;
}A processor also supports @BeforeGroup and @AfterGroup methods, which must not have any parameter and return void values. Any other result would be ignored.
These methods are used by the runtime to mark a chunk of the data in a way which is estimated good for the execution flow size.
Because the size is estimated, the size of a group can vary. It is even possible to have groups of size 1.
|
It is recommended to batch records, for performance reasons:
@BeforeGroup
public void initBatch() {
// ...
}
@AfterGroup
public void endBatch() {
// ...
}You can optimize the data batch processing by using the maxBatchSize parameter. This parameter is automatically implemented on the component when it is deployed to a Talend application. Only the logic needs to be implemented. You can however customize its value setting in your LocalConfiguration the property _maxBatchSize.value - for the family - or ${component simple class name}._maxBatchSize.value - for a particular component, otherwise its default will be 1000. If you replace value by active, you can also configure if this feature is enabled or not. This is useful when you don’t want to use it at all. Learn how to implement chunking/bulking in this document.
Defining output connections
In some cases, you may need to split the output of a processor in two or more connections. A common example is to have "main" and "reject" output connections where parts of the incoming data are passed to a specific bucket for later processing.
Talend Component Kit supports two types of output connections: Flow and Reject.
-
Flow is the main and standard output connection.
-
The Reject connection handles records rejected during the processing. A component can only have one reject connection, if any. Its name must be
REJECTto be processed correctly in Talend applications.
| You can also define the different output connections of your component in the Starter. |
To define an output connection, you can use @Output as replacement of the returned value in the @ElementListener:
@ElementListener
public void map(final MyData data, @Output final OutputEmitter<MyNewData> output) {
output.emit(createNewData(data));
}Alternatively, you can pass a string that represents the new branch:
@ElementListener
public void map(final MyData data,
@Output final OutputEmitter<MyNewData> main,
@Output("REJECT") final OutputEmitter<MyNewDataWithError> rejected) {
if (isRejected(data)) {
rejected.emit(createNewData(data));
} else {
main.emit(createNewData(data));
}
}
// or
@ElementListener
public MyNewData map(final MyData data,
@Output("REJECT") final OutputEmitter<MyNewDataWithError> rejected) {
if (isSuspicious(data)) {
rejected.emit(createNewData(data));
return createNewData(data); // in this case the processing continues but notifies another channel
}
return createNewData(data);
}Defining conditional outputs flows
Processors @ElementListener methods can declare several output flows. During the design phase, all output flows are typically available. However, in some cases, we may want to disable certain flows based on the user’s configuration settings. In such instances, a service will be called to determine the available output flows. (Currently, only Studio supports this feature.)
-
A processor without @ConditionalOutputFlows keep the current behavior. All declared flows are visible at design time
-
A processor with @ConditionalOutputFlows has its output flows list conditioned by its configuration
-
The @ConditionalOutputFlows has one parameter: the name of a @AvailableOutputFlows service: @ConditionalOutputFlows("the_name")
-
Each processor in a same TCK container can use a different service to retrieve the list of available output flows
-
So several services can be annotated with @AvailableOutputFlows but their name must be different @AvailableOutputFlows("the_name"), @AvailableOutputFlow("another_name"), …
-
-
-
The return type of a @AvailableOutputFlows service is a List<String>, the build should fail if not.
@Processor(name = "Processor")
@ConditionalOutputFlows("my_service_that_return_active_flows")
public class MyProcessor implements Serializable {
@ElementListener
public void process(@Input final Record input,
@Output final OutputEmitter<Record> main,
@Output("second_flow") final OutputEmitter<Record> second,
@Output("third_flow") final OutputEmitter<Record> third) {
[.........]
}
}
@AvailableOutputFlows("my_service_that_return_active_flows")
//After the @Option, must follow ("configuration")
public Collection<String> getAvailableFlows(@Option("configuration") Config config) {
final List<String> flows = Arrays.asList("default", "second_flow");
if (config.isABoolean()) {
flows.add("third_flow");
}
return flows;
}Defining multiple inputs
Having multiple inputs is similar to having multiple outputs, except that an OutputEmitter wrapper is not needed:
@ElementListener
public MyNewData map(@Input final MyData data, @Input("input2") final MyData2 data2) {
return createNewData(data1, data2);
}@Input takes the input name as parameter. If no name is set, it defaults to the "main (default)" input branch. It is recommended to use the default branch when possible and to avoid naming branches according to the component semantic.
Implementing batch processing
What is batch processing
Batch processing refers to the way execution environments process batches of data handled by a component using a grouping mechanism.
By default, the execution environment of a component automatically decides how to process groups of records and estimates an optimal group size depending on the system capacity. With this default behavior, the size of each group could sometimes be optimized for the system to handle the load more effectively or to match business requirements.
For example, real-time or near real-time processing needs often imply processing smaller batches of data, but more often. On the other hand, a one-time processing without business contraints is more effectively handled with a batch size based on the system capacity.
Final users of a component developed with the Talend Component Kit that integrates the batch processing logic described in this document can override this automatic size. To do that, a maxBatchSize option is available in the component settings and allows to set the maximum size of each group of data to process.
A component processes batch data as follows:
-
Case 1 - No
maxBatchSizeis specified in the component configuration. The execution environment estimates a group size of 4. Records are processed by groups of 4. -
Case 2 - The runtime estimates a group size of 4 but a
maxBatchSizeof 3 is specified in the component configuration. The system adapts the group size to 3. Records are processed by groups of 3.
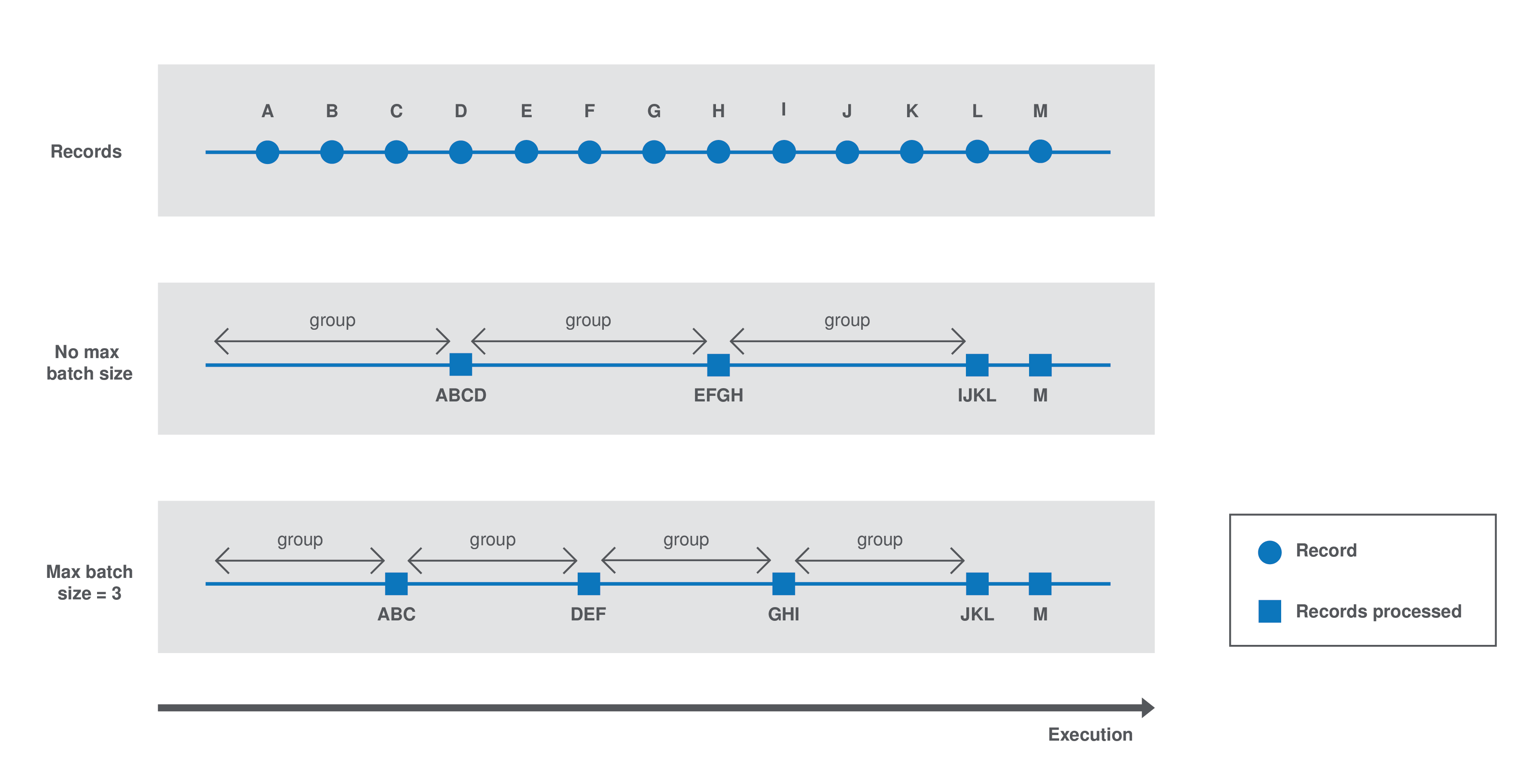
Batch processing implementation logic
Batch processing relies on the sequence of three methods: @BeforeGroup, @ElementListener, @AfterGroup, that you can customize to your needs as a component Developer.
| The group size automatic estimation logic is automatically implemented when a component is deployed to a Talend application. |
Each group is processed as follows until there is no record left:
-
The
@BeforeGroupmethod resets a record buffer at the beginning of each group. -
The records of the group are assessed one by one and placed in the buffer as follows: The
@ElementListenermethod tests if the buffer size is greater or equal to the definedmaxBatchSize. If it is, the records are processed. If not, then the current record is buffered. -
The previous step happens for all records of the group. Then the
@AfterGroupmethod tests if the buffer is empty.
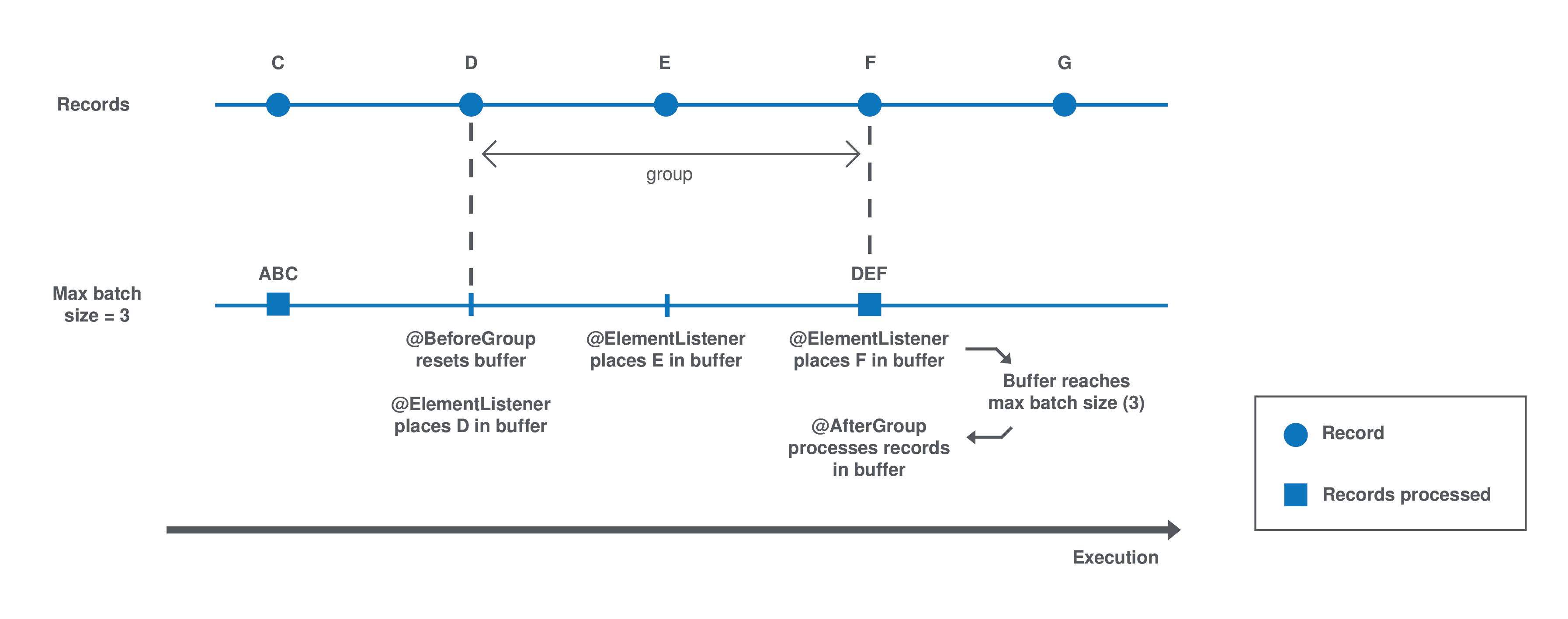
You can define the following logic in the processor configuration:
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Collection;
import javax.json.JsonObject;
import org.talend.sdk.component.api.processor.AfterGroup;
import org.talend.sdk.component.api.processor.BeforeGroup;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.processor.Processor;
@Processor(name = "BulkOutputDemo")
public class BulkProcessor implements Serializable {
private Collection<JsonObject> buffer;
@BeforeGroup
public void begin() {
buffer = new ArrayList<>();
}
@ElementListener
public void bufferize(final JsonObject object) {
buffer.add(object);
}
@AfterGroup
public void commit() {
// saves buffered records at once (bulk)
}
}You can also use the condensed syntax for this kind of processor:
@Processor(name = "BulkOutputDemo")
public class BulkProcessor implements Serializable {
@AfterGroup
public void commit(final Collection<Record> records) {
// saves records
}
}When using the @aftergroup feature, it can be helpful to determine if it’s the last call (last group). You can now annotate a Boolean with @lastgroup as a parameter of the method. This Boolean will be set to true for the final call, which can be useful for performing additional actions once all records have been processed.
For example, here is a scenario inspired by Snowflake:
Batches of records are staged within each @aftergroup call. Once all data has been staged, a final #commitBulkLoad call is executed. This action must be performed after all data has been staged. This process returns all rejected data, which is then transformed into TCK records and sent to the 'REJECT' flow.
@AfterGroup
public void afterGroup(@Output("REJECT") final OutputEmitter<Record> rejected, @LastGroup Boolean last) {
database.pushToStaging(records);
if(last){
List<Data> dataToReject = database.commitBulkLoad();
dataToReject.stream().map(d -> convertToRecord(d)).each(r -> rejected.emit(d));
}
}
When writing tests for components, you can force the maxBatchSize parameter value by setting it with the following syntax: <configuration prefix>.$maxBatchSize=10.
|
You can learn more about processors in this document.
Shortcut syntax for bulk output processors
For the case of output components (not emitting any data) using bulking you can pass the list of records to the @AfterGroup method:
@Processor(name = "DocOutput")
public class DocOutput implements Serializable {
@AfterGroup
public void onCommit(final Collection<Record> records) {
// save records
}
}