Creating your first component
This tutorial walks you through the most common iteration steps to create a component with Talend Component Kit and to deploy it to Talend Open Studio.
The component created in this tutorial is a simple processor that reads data coming from the previous component in a job or pipeline and displays it in the console logs of the application, along with an additional information entered by the final user.
| The component designed in this tutorial is a processor and does not require nor show any datastore and dataset configuration. Datasets and datastores are required only for input and output components. |
Prerequisites
To get your development environment ready and be able to follow this tutorial:
-
Download and install a Java JDK 1.8 or greater.
-
Download and install Talend Open Studio. For example, from Sourceforge.
-
Download and install IntelliJ.
-
Download the Talend Component Kit plugin for IntelliJ. The detailed installation steps for the plugin are available in this document.
Generate a component project
The first step in this tutorial is to generate a component skeleton using the Starter embedded in the Talend Component Kit plugin for IntelliJ.
-
Start IntelliJ and create a new project. In the available options, you should see Talend Component.

-
Make sure that a Project SDK is selected. Then, select Talend Component and click Next.
The Talend Component Kit Starter opens. -
Enter the component and project metadata. Change the default values, for example as presented in the screenshot below:
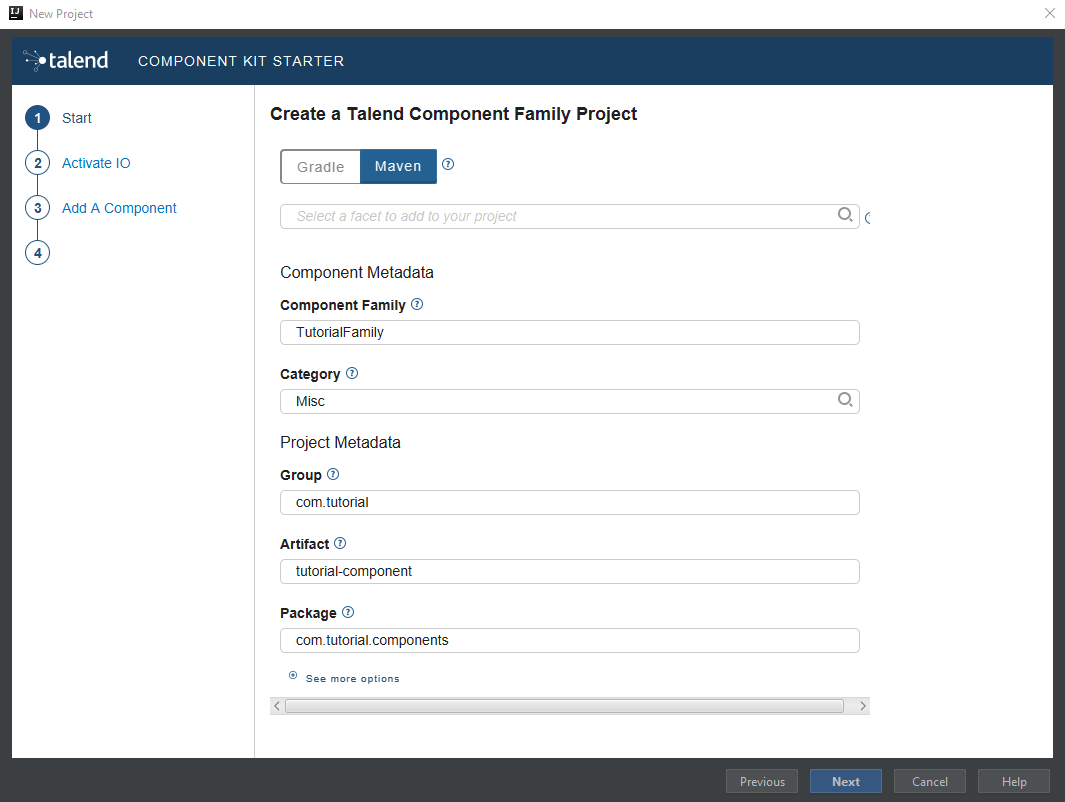
-
The Component Family and the Category will be used later in Talend Open Studio to find the new component.
-
Project metadata is mostly used to identify the project structure. A common practice is to replace 'company' in the default value by a value of your own, like your domain name.
-
-
Once the metadata is filled, select Add a component. A new screen is displayed in the Talend Component Kit Starter that lets you define the generic configuration of the component. By default, new components are processors.
-
Enter a valid Java name for the component. For example, Logger.
-
Select Configuration Model and add a string type field named
level. This input field will be used in the component configuration for final users to enter additional information to display in the logs.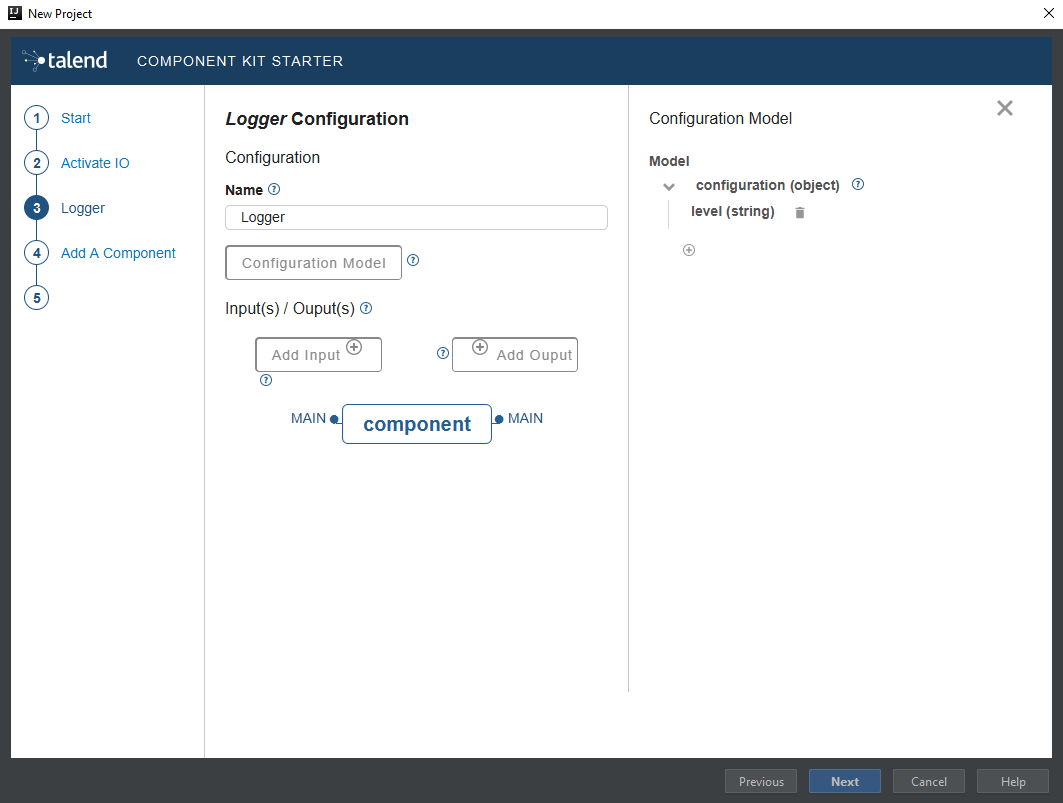
-
In the Input(s) / Output(s) section, click the default MAIN input branch to access its detail, and make sure that the record model is set to Generic. Leave the Name of the branch with its default
MAINvalue.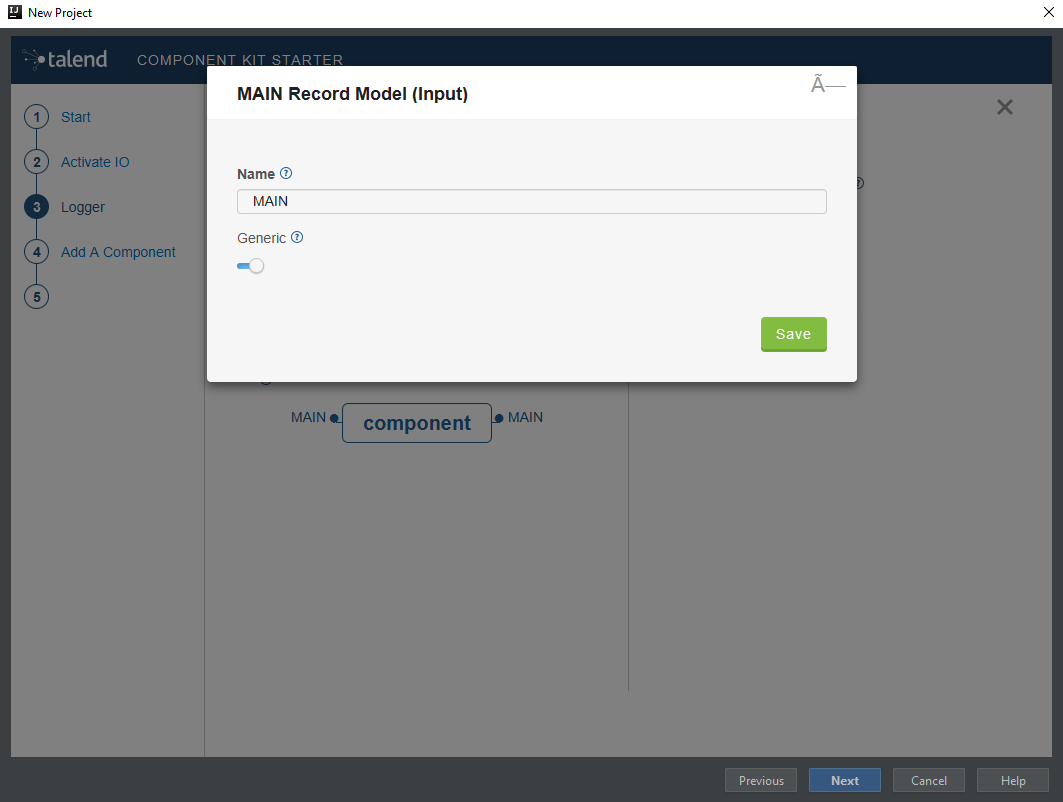
-
Repeat the same step for the default MAIN output branch.
Because the component is a processor, it has an output branch by default. A processor without any output branch is considered an output component. You can create output components when the Activate IO option is selected. -
Click Next and check the name and location of the project, then click Finish to generate the project in the IDE.
At this point, your component is technically already ready to be compiled and deployed to Talend Open Studio. But first, take a look at the generated project:
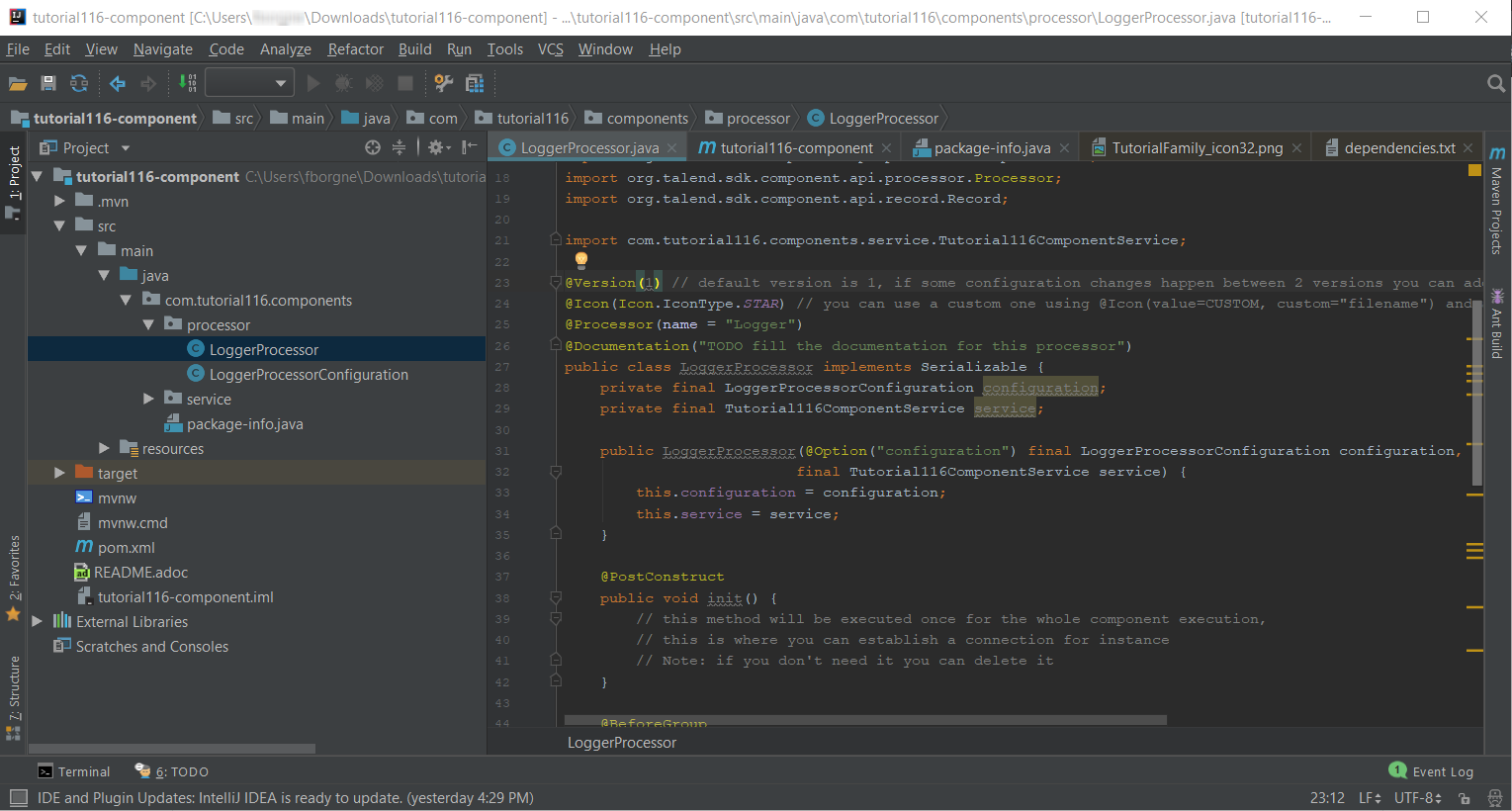
-
Two classes based on the name and type of component defined in the Talend Component Kit Starter have been generated:
-
LoggerProcessor is where the component logic is defined
-
LoggerProcessorConfiguration is where the component layout and configurable fields are defined, including the level string field that was defined earlier in the configuration model of the component.
-
-
The package-info.java file contains the component metadata defined in the Talend Component Kit Starter, such as family and category.
-
You can notice as well that the elements in the tree structure are named after the project metadata defined in the Talend Component Kit Starter.
These files are the starting point if you later need to edit the configuration, logic, and metadata of the component.
There is more that you can do and configure with the Talend Component Kit Starter. This tutorial covers only the basics. You can find more information in this document.
Compile and deploy the component to Talend Open Studio
Without modifying the component code generated from the Starter, you can compile the project and deploy the component to a local instance of Talend Open Studio.
The logic of the component is not yet implemented at that stage. Only the configurable part specified in the Starter will be visible. This step is useful to confirm that the basic configuration of the component renders correctly.
Before starting to run any command, make sure that Talend Open Studio is not running.
-
From the component project in IntelliJ, open a Terminal and make sure that the selected directory is the root of the project. All commands shown in this tutorial are performed from this location.
-
Compile the project by running the following command:
mvnw clean install.
Themvnwcommand refers to the Maven wrapper that is embedded in Talend Component Kit. It allows to use the right version of Maven for your project without having to install it manually beforehand. -
Once the command is executed and you see BUILD SUCCESS in the terminal, deploy the component to your local instance of Talend Open Studio using the following command:
mvnw talend-component:deploy-in-studio -Dtalend.component.studioHome="<path to Talend Open Studio home>".Replace the path with your own value. If the path contains spaces (for example, Program Files), enclose it with double quotes. -
Make sure the build is successful.
-
Open Talend Open Studio and create a new Job:
-
Find the new component by looking for the family and category specified in the Talend Component Kit Starter. You can add it to your job and open its settings.
-
Notice that the level field specified in the configuration model of the component in the Talend Component Kit Starter is present.
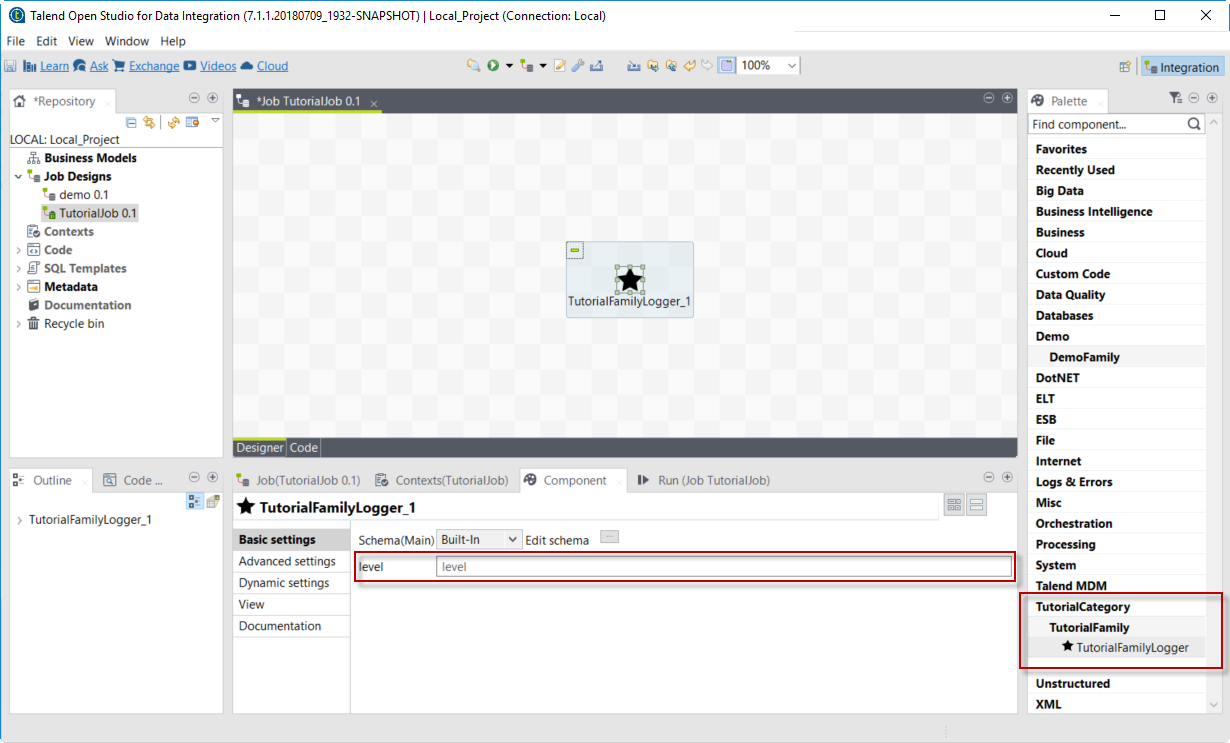
-
At this point, the new component is available in Talend Open Studio, and its configurable part is already set. But the component logic is still to be defined.
Edit the component
You can now edit the component to implement its logic: reading the data coming through the input branch to display that data in the execution logs of the job. The value of the level field that final users can fill also needs to be changed to uppercase and displayed in the logs.
-
Save the job created earlier and close Talend Open Studio.
-
Go back to the component development project in IntelliJ and open the LoggerProcessor class. This is the class where the component logic can be defined.
-
Look for the
@ElementListenermethod. It is already present and references the default input branch that was defined in the Talend Component Kit Starter, but it is not complete yet. -
To be able to log the data in input to the console, add the following lines:
//Log read input to the console with uppercase level. System.out.println("["+configuration.getLevel().toUpperCase()+"] "+defaultInput);The
@ElementListenermethod now looks as follows:@ElementListener public void onNext( @Input final Record defaultInput) { //Reads the input. //Log read input to the console with uppercase level. System.out.println("["+configuration.getLevel().toUpperCase()+"] "+defaultInput); }
-
Open a Terminal again to compile the project and deploy the component again. To do that, run successively the two following commands:
-
mvnw clean install -
`mvnw talend-component:deploy-in-studio -Dtalend.component.studioHome="<path to Talend Open Studio home>"
-
The update of the component logic should now be deployed. After restarting Talend Open Studio, you will be ready to build a job and use the component for the first time.
To learn the different possibilities and methods available to develop more complex logics, refer to this document.
If you want to avoid having to close and re-open Talend Open Studio every time you need to make an edit, you can enable the developer mode, as explained in this document.
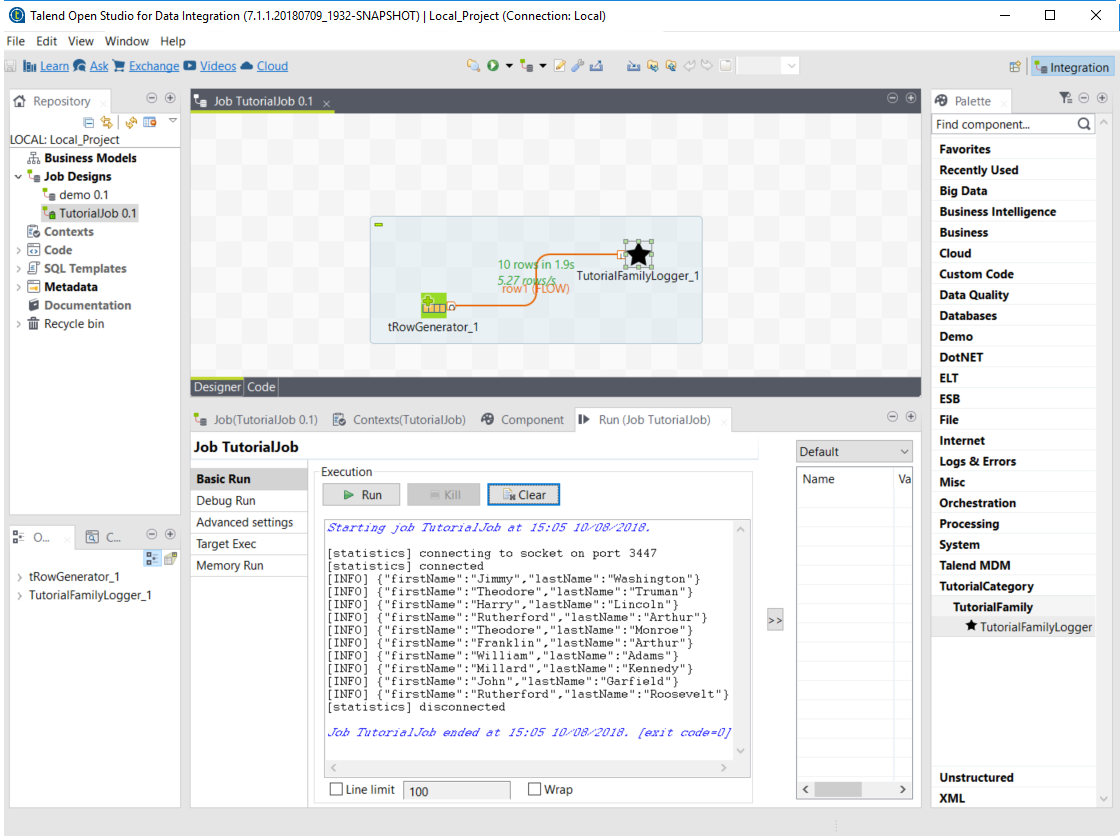
Build a job with the component
As the component is now ready to be used, it is time to create a job and check that it behaves as intended.
-
Open Talend Open Studio again and go to the job created earlier. The new component is still there.
-
Add a tRowGenerator component and connect it to the logger.
-
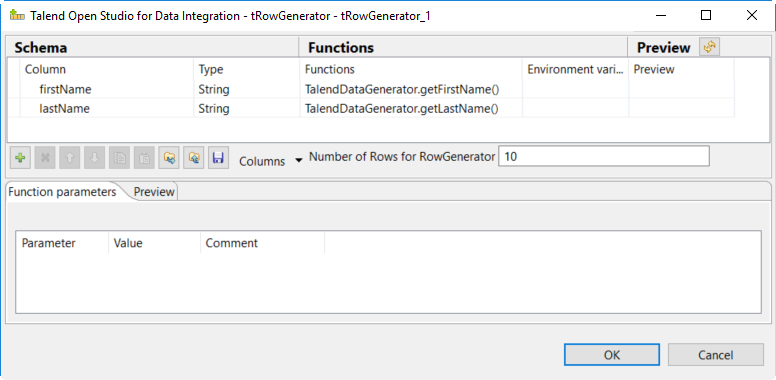
Double-click the tRowGenerator to specify the data to generate:
-
Add a first column named
firstNameand select the TalendDataGenerator.getFirstName() function. -
Add a second column named 'lastName' and select the TalendDataGenerator.getLastName() function.
-
Set the Number of Rows for RowGenerator to
10.
-
-
Validate the tRowGenerator configuration.
-
Open the TutorialFamilyLogger component and set the level field to
info.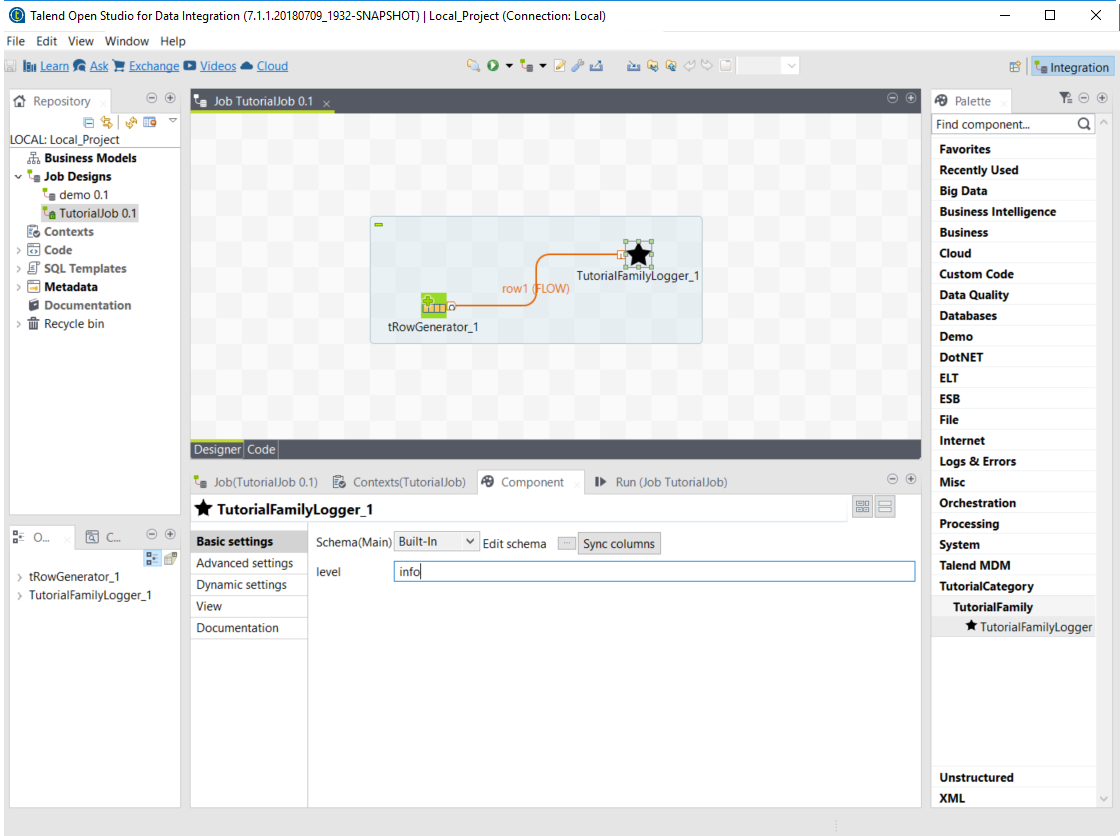
-
Go to the Run tab of the job and run the job.
The job is executed. You can observe in the console that each of the 10 generated rows is logged, and that theinfovalue entered in the logger is also displayed with each record, in uppercase.
Generating a project using the Component Kit Starter
The Component Kit Starter lets you design your components configuration and generates a ready-to-implement project structure.
The Starter is available on the web or as an IntelliJ plugin.
This tutorial shows you how to use the Component Kit Starter to generate new components for MySQL databases. Before starting, make sure that you have correctly setup your environment. See this section.
| When defining a project using the Starter, do not refresh the page to avoid losing your configuration. |
Configuring the project
Before being able to create components, you need to define the general settings of the project:
-
Create a folder on your local machine to store the resource files of the component you want to create. For example,
C:/my_components. -
Open the Starter in the web browser of your choice.
-
Select your build tool. This tutorial uses Maven.
-
Add any facet you need. For example, add the Talend Component Kit Testing facet to your project to automatically generate unit tests for the components created in the project.
-
Enter the Component Family of the components you want to develop in the project. This name must be a valid java name and is recommended to be capitalized, for example 'MySQL'.
Once you have implemented your components in the Studio, this name is displayed in the Palette to group all of the MySQL-related components you develop, and is also part of your component name. -
Select the Category of the components you want to create in the current project. As MySQL is a kind of database, select Databases in this tutorial.
This Databases category is used and displayed as the parent family of the MySQL group in the Palette of the Studio. -
Complete the project metadata by entering the Group, Artifact and Package.
-
By default, you can only create processors. If you need to create Input or Output components, select Activate IO. By doing this:
-
Two new menu entries let you add datasets and datastores to your project, as they are required for input and output components.
Input and Output components without dataset (itself containing a datastore) will not pass the validation step when building the components. Learn more about datasets and datastores in this document. -
An Input component and an Output component are automatically added to your project and ready to be configured.
-
Components added to the project using Add A Component can now be processors, input or output components.
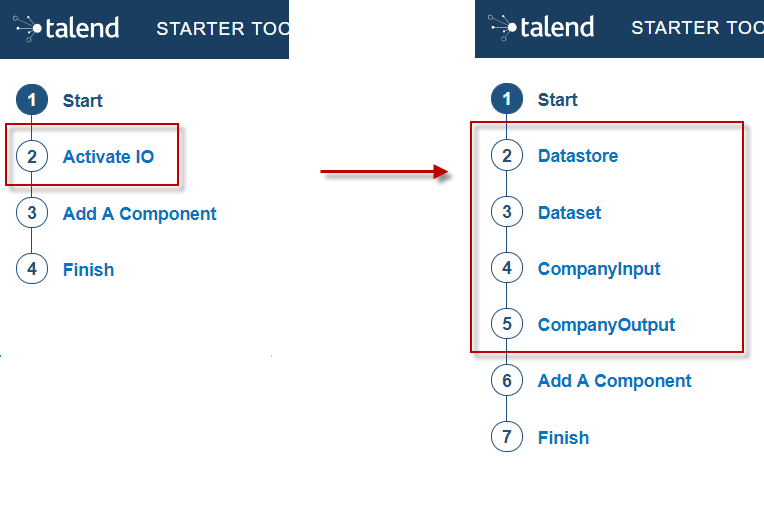
-
Defining a Datastore
A datastore represents the data needed by an input or output component to connect to a database.
When building a component, the validateDataSet validation checks that each input or output (processor without output branch) component uses a dataset and that this dataset has a datastore.
You can define one or several datastores if you have selected the Activate IO step.
-
Select Datastore. The list of datastores opens. By default, a datastore is already open but not configured. You can configure it or create a new one using Add new Datastore.
-
Specify the name of the datastore. Modify the default value to a meaningful name for your project.
This name must be a valid Java name as it will represent the datastore class in your project. It is a good practice to start it with an uppercase letter. -
Edit the datastore configuration. Parameter names must be valid Java names. Use lower case as much as possible. A typical configuration includes connection details to a database:
-
url
-
username
-
password.
-
-
Save the datastore configuration.
Defining a Dataset
A dataset represents the data coming from or sent to a database and needed by input and output components to operate.
The validateDataSet validation checks that each input or output (processor without output branch) component uses a dataset and that this dataset has a datastore.
You can define one or several datasets if you have selected the Activate IO step.
-
Select Dataset. The list of datasets opens. By default, a dataset is already open but not configured. You can configure it or create a new one using the Add new Dataset button.
-
Specify the name of the dataset. Modify the default value to a meaningful name for your project.
This name must be a valid Java name as it will represent the dataset class in your project. It is a good practice to start it with an uppercase letter. -
Edit the dataset configuration. Parameter names must be valid Java names. Use lower case as much as possible. A typical configuration includes details of the data to retrieve:
-
Datastore to use (that contains the connection details to the database)
-
table name
-
data
-
-
Save the dataset configuration.
Creating an Input component
To create an input component, make sure you have selected Activate IO.
When clicking Add A Component in the Starter, a new step allows you to define a new component in your project.
The intent in this tutorial is to create an input component that connects to a MySQL database, executes a SQL query and gets the result.
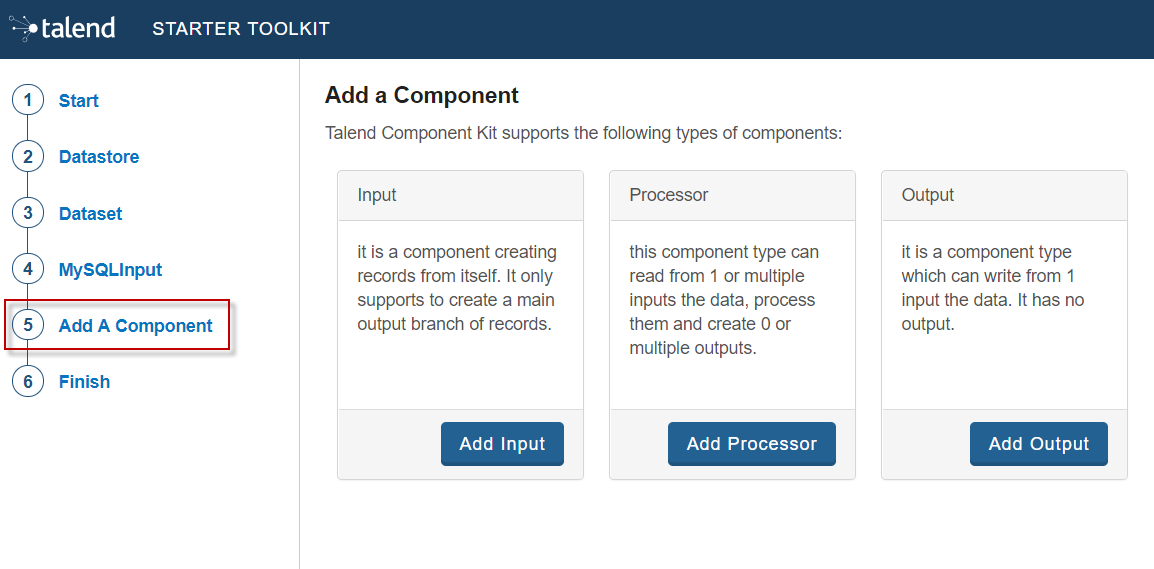
-
Choose the component type. Input in this case.
-
Enter the component name. For example, MySQLInput.
-
Click Configuration model. This button lets you specify the required configuration for the component. By default, a dataset is already specified.
-
For each parameter that you need to add, click the (+) button on the right panel. Enter the parameter name and choose its type then click the tick button to save the changes.
In this tutorial, to be able to execute a SQL query on the Input MySQL database, the configuration requires the following parameters:+-
a dataset (which contains the datastore with the connection information)
-
a timeout parameter.
Closing the configuration panel on the right does not delete your configuration. However, refreshing the page resets the configuration.
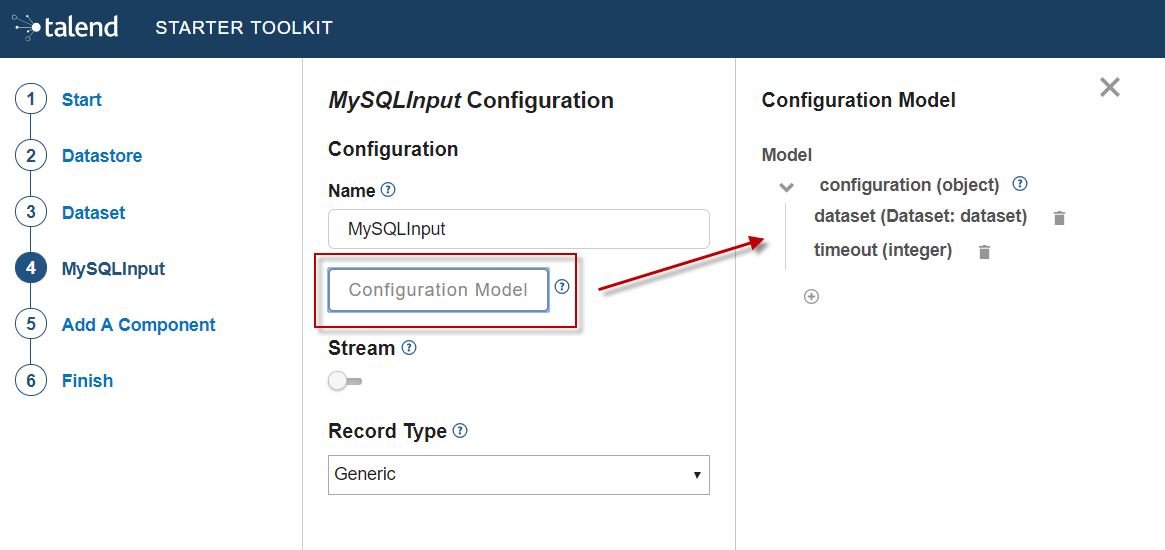
-
-
Specify whether the component issues a stream or not. In this tutorial, the MySQL input component created is an ordinary (non streaming) component. In this case, leave the Stream option disabled.
-
Select the Record Type generated by the component. In this tutorial, select Generic because the component is designed to generate records in the default
Recordformat.
You can also select Custom to define a POJO that represents your records.
Your input component is now defined. You can add another component or generate and download your project.
Creating a Processor component
When clicking Add A Component in the Starter, a new step allows you to define a new component in your project. The intent in this tutorial is to create a simple processor component that receives a record, logs it and returns it at it is.
|
If you did not select Activate IO, all new components you add to the project are processors by default. If you selected Activate IO, you can choose the component type. In this case, to create a Processor component, you have to manually add at least one output. |
-
If required, choose the component type: Processor in this case.
-
Enter the component name. For example, RecordLogger, as the processor created in this tutorial logs the records.
-
Specify the Configuration Model of the component. In this tutorial, the component doesn’t need any specific configuration. Skip this step.
-
Define the Input(s) of the component. For each input that you need to define, click Add Input. In this tutorial, only one input is needed to receive the record to log.
-
Click the input name to access its configuration. You can change the name of the input and define its structure using a POJO. If you added several inputs, repeat this step for each one of them.
The input in this tutorial is a generic record. Enable the Generic option and click Save.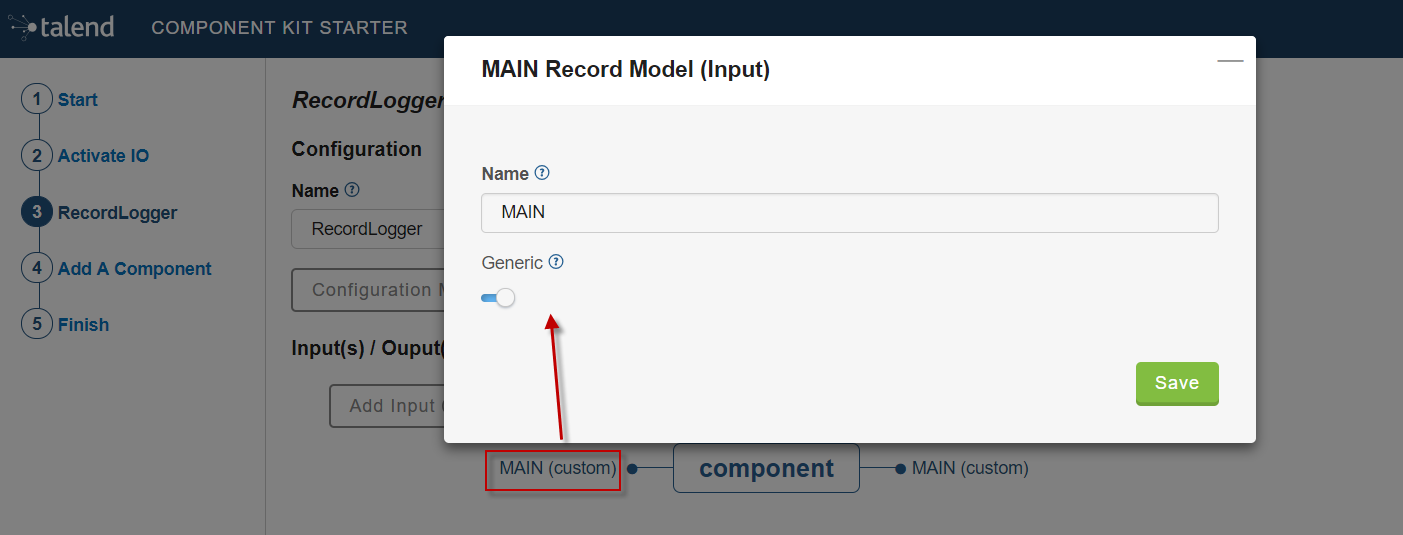
-
Define the Output(s) of the component. For each output that you need to define, click Add Output. The first output must be named
MAIN. In this tutorial, only one generic output is needed to return the received record.
Outputs can be configured the same way as inputs (see previous steps).
You can define a reject output connection by naming itREJECT. This naming is used by Talend applications to automatically set the connection type to Reject.
Your processor component is now defined. You can add another component or generate and download your project.
Creating an Output component
To create an output component, make sure you have selected Activate IO.
When clicking Add A Component in the Starter, a new step allows you to define a new component in your project.
The intent in this tutorial is to create an output component that receives a record and inserts it into a MySQL database table.
| Output components are Processors without any output. In other words, the output is a processor that does not produce any records. |
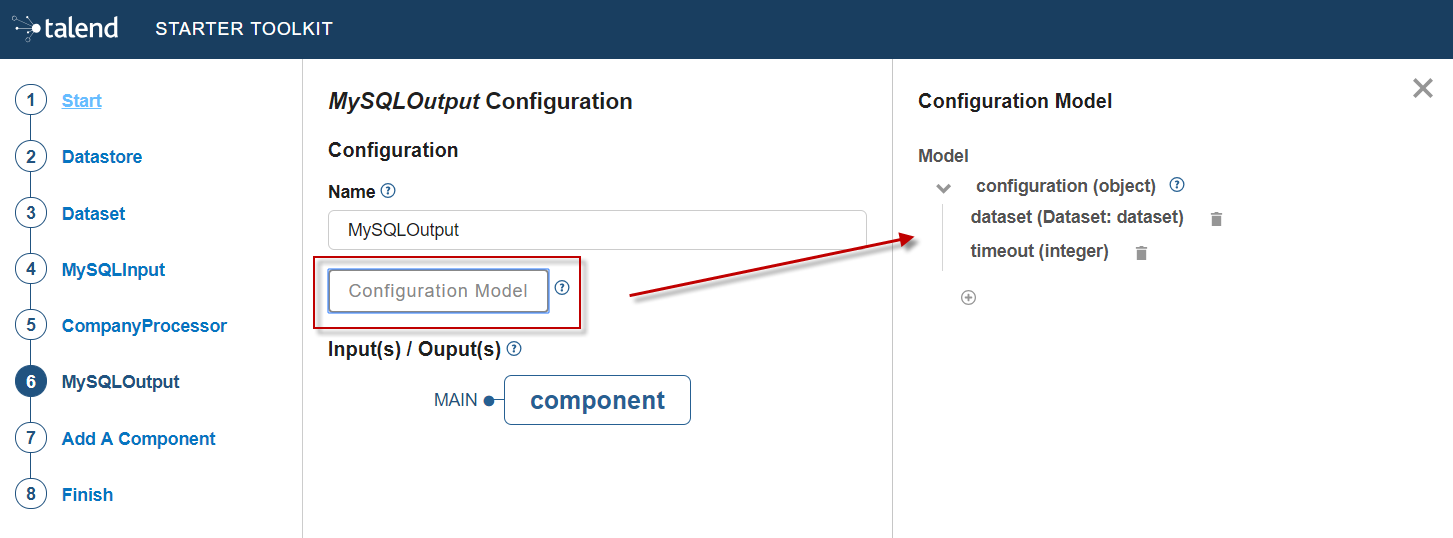
-
Choose the component type. Output in this case.
-
Enter the component name. For example, MySQLOutput.
-
Click Configuration Model. This button lets you specify the required configuration for the component. By default, a dataset is already specified.
-
For each parameter that you need to add, click the (+) button on the right panel. Enter the name and choose the type of the parameter, then click the tick button to save the changes.
In this tutorial, to be able to insert a record in the output MySQL database, the configuration requires the following parameters:+-
a dataset (which contains the datastore with the connection information)
-
a timeout parameter.
Closing the configuration panel on the right does not delete your configuration. However, refreshing the page resets the configuration.
-
-
Define the Input(s) of the component. For each input that you need to define, click Add Input. In this tutorial, only one input is needed.
-
Click the input name to access its configuration. You can change the name of the input and define its structure using a POJO. If you added several inputs, repeat this step for each one of them.
The input in this tutorial is a generic record. Enable the Generic option and click Save.
| Do not create any output because the component does not produce any record. This is the only difference between an output an a processor component. |
Your output component is now defined. You can add another component or generate and download your project.
Generating and downloading the final project
Once your project is configured and all the components you need are created, you can generate and download the final project. In this tutorial, the project was configured and three components of different types (input, processor and output) have been defined.
-
Click Finish on the left panel. You are redirected to a page that summarizes the project. On the left panel, you can also see all the components that you added to the project.
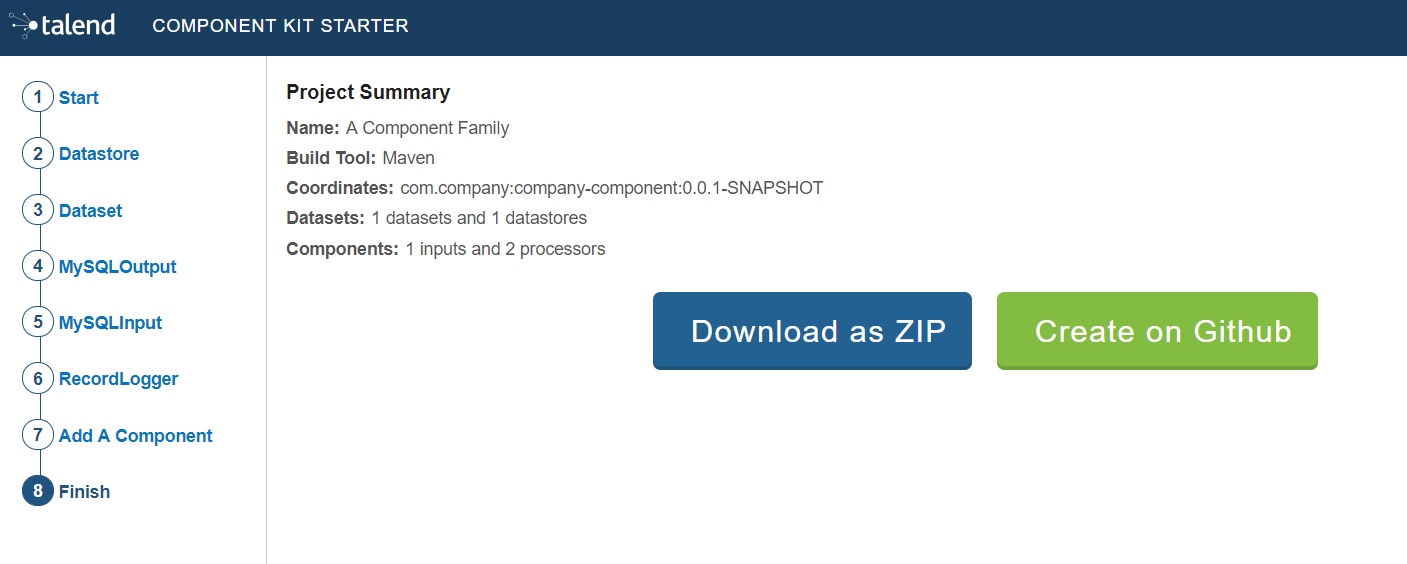
-
Generate the project using one of the two options available:
-
Download it locally as a ZIP file using the Download as ZIP button.
-
Create a GitHub repository and push the project to it using the Create on Github button.
-
In this tutorial, the project is downloaded to the local machine as a ZIP file.
Compiling and exploring the generated project files
Once the package is available on your machine, you can compile it using the build tool selected when configuring the project.
-
In the tutorial, Maven is the build tool selected for the project.
In the project directory, execute themvn packagecommand.
If you don’t have Maven installed on your machine, you can use the Maven wrapper provided in the generated project, by executing the./mvnw packagecommand.
The generated project code contains documentation that can guide and help you implementing the component logic. Import the project to your favorite IDE to start the implementation.
Generating a project using an OpenAPI JSON descriptor
The Component Kit Starter allows you to generate a component development project from an OpenAPI JSON descriptor.
-
Open the Starter in the web browser of your choice.
-
Enable the OpenAPI mode using the toggle in the header.

-
Go to the API menu.
-
Paste the OpenAPI JSON descriptor in the right part of the screen. All the described endpoints are detected.
-
Unselect the endpoints that you do not want to use in the future components. By default, all detected endpoints are selected.
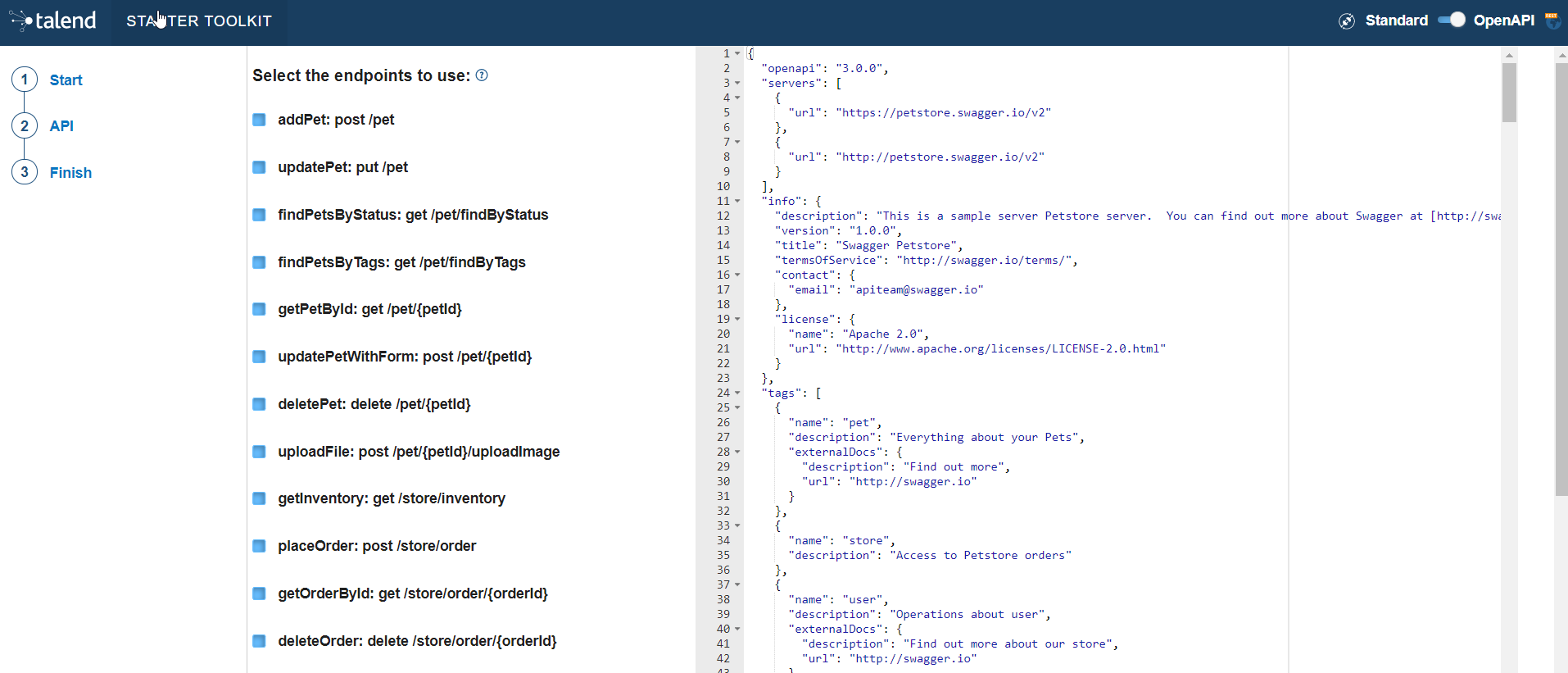
-
Go to the Finish menu.
-
Download the project.
When exploring the project generated from an OpenAPI descriptor, you can notice the following elements:
-
sources
-
the API dataset
-
an HTTP client for the API
-
a connection folder containing the component configuration. By default, the configuration is only made of a simple datastore with a
baseUrlparameter.
Talend Input component for Hazelcast
This tutorial walks you through the creation, from scratch, of a complete Talend input component for Hazelcast using the Talend Component Kit (TCK) framework.
Hazelcast is an in-memory distributed system that can store data, which makes it a good example of input component for distributed systems. This is enough for you to get started with this tutorial, but you can find more information about it here: hazelcast.org/.
Creating the project
A TCK project is a simple Java project with specific configurations and dependencies. You can choose your preferred build tool from Maven as TCK supports both. In this tutorial, Maven is used.
The first step consists in generating the project structure using Talend Starter Toolkit .
-
Go to starter-toolkit.talend.io/ and fill in the project information as shown in the screenshots below, then click Finish and Download as ZIP.
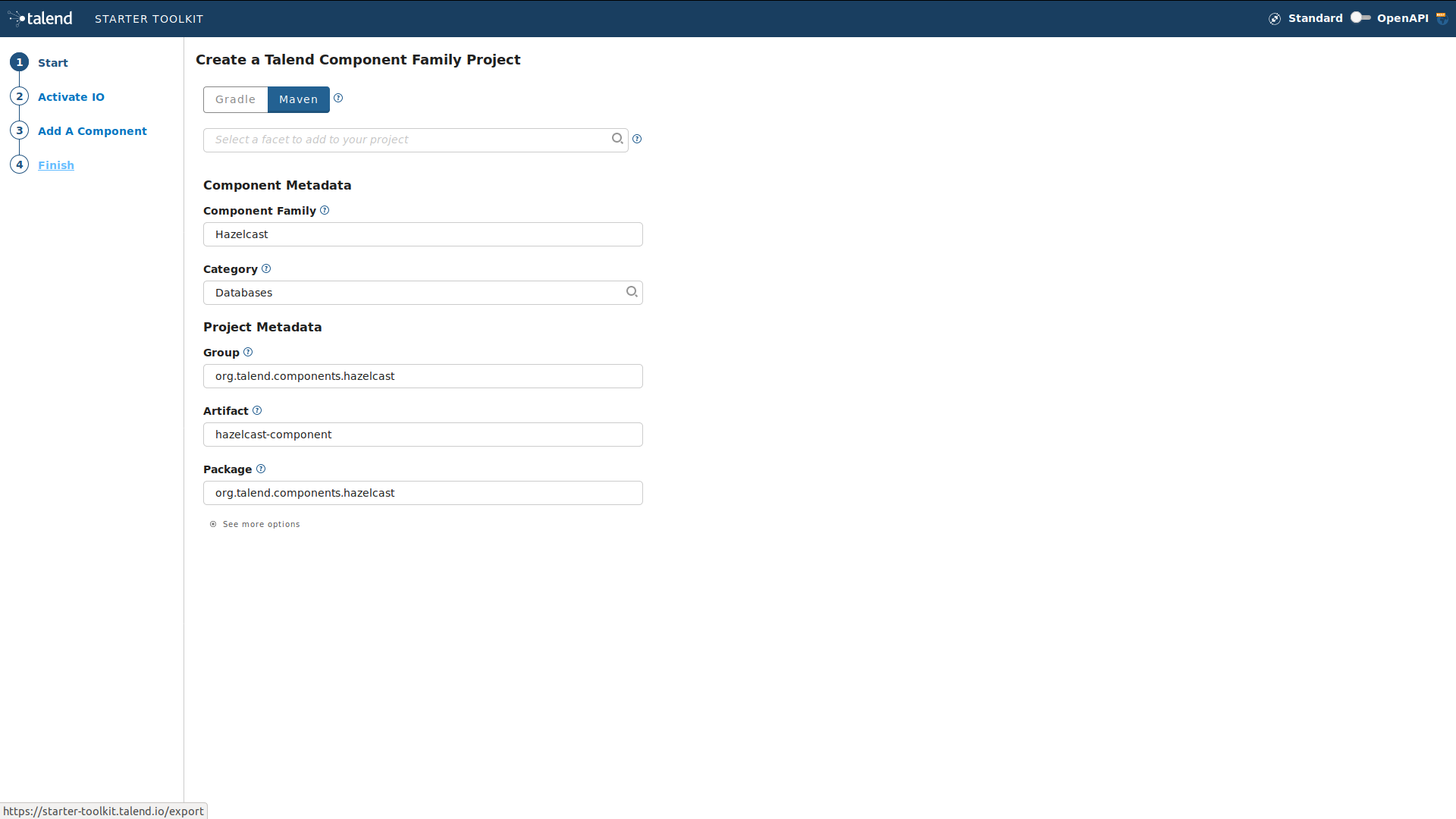
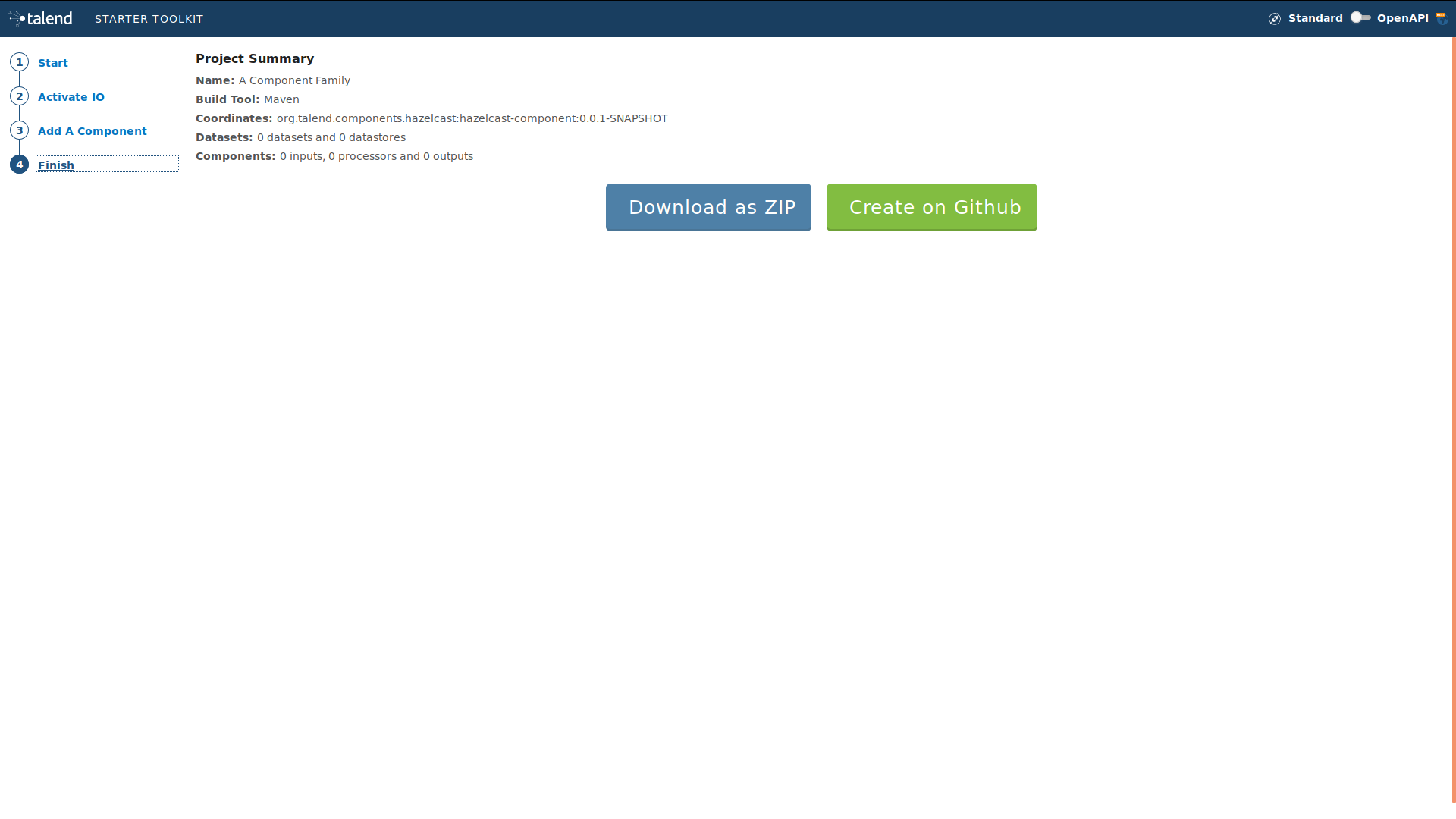
-
Extract the ZIP file into your workspace and import it to your preferred IDE. This tutorial uses Intellij IDE, but you can use Eclipse or any other IDE that you are comfortable with.
You can use the Starter Toolkit to define the full configuration of the component, but in this tutorial some parts are configured manually to explain key concepts of TCK. The generated
pom.xmlfile of the project looks as follows:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.talend.components.hazelcast</groupId> <artifactId>hazelcast-component</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>Component Hazelcast</name> <description>A generated component project</description> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!-- Set it to true if you want the documentation to be rendered as HTML and PDF You can also use it in the command line: -Dtalend.documentation.htmlAndPdf=true --> <talend.documentation.htmlAndPdf>false</talend.documentation.htmlAndPdf> <!-- if you want to deploy into the Studio you can use the related goal: mvn package talend-component:deploy-in-studio -Dtalend.component.studioHome=/path/to/studio TIP: it is recommended to set this property into your settings.xml in an active by default profile. --> <talend.component.studioHome /> </properties> <dependencies> <dependency> <groupId>org.talend.sdk.component</groupId> <artifactId>component-api</artifactId> <version>1.1.12</version> <scope>provided</scope> </dependency> </dependencies> <build> <extensions> <extension> <groupId>org.talend.sdk.component</groupId> <artifactId>talend-component-maven-plugin</artifactId> <version>1.1.12</version> </extension> </extensions> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.14.0</version> <configuration> <source>1.8</source> <target>1.8</target> <forceJavacCompilerUse>true</forceJavacCompilerUse> <compilerId>javac</compilerId> <fork>true</fork> <compilerArgs> <arg>-parameters</arg> </compilerArgs> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0-M3</version> <configuration> <trimStackTrace>false</trimStackTrace> <runOrder>alphabetical</runOrder> </configuration> </plugin> </plugins> </build> </project> -
Change the
nametag to a more relevant value, for example: <name>Component Hazelcast</name>.-
The
component-apidependency provides the necessary API to develop the components. -
talend-component-maven-pluginprovides build and validation tools for the component development.The Java compiler also needs a Talend specific configuration for the components to work correctly. The most important is the -parameters option that preserves the parameter names needed for introspection features that TCK relies on.
-
-
Download the mvn dependencies declared in the
pom.xmlfile:$ mvn clean compileYou should get a
BUILD SUCCESSat this point:[INFO] Scanning for projects... [INFO] [INFO] -----< org.talend.components.hazelcast:talend-component-hazelcast >----- [INFO] Building Component :: Hazelcast 1.0.0-SNAPSHOT [INFO] --------------------------------[ jar ]--------------------------------- [INFO] ... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 1.311 s [INFO] Finished at: 2019-09-03T11:42:41+02:00 [INFO] ------------------------------------------------------------------------ -
Create the project structure:
$ mkdir -p src/main/java $ mkdir -p src/main/resources -
Create the component Java packages.
Packages are mandatory in the component model and you cannot use the default one (no package). It is recommended to create a unique package per component to be able to reuse it as dependency in other components, for example to guarantee isolation while writing unit tests. $ mkdir -p src/main/java/org/talend/components/hazelcast $ mkdir -p src/main/resources/org/talend/components/hazelcast
The project is now correctly set up. The next steps consist in registering the component family and setting up some properties.
Registering the Hazelcast components family
Registering every component family allows the component server to properly load the components and to ensure they are available in Talend Studio.
Creating the package-info.java file
The family registration happens via a package-info.java file that you have to create.
Move to the src/main/java/org/talend/components/hazelcast package and create a package-info.java file:
@Components(family = "Hazelcast", categories = "Databases")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Components;
import org.talend.sdk.component.api.component.Icon;-
@Components: Declares the family name and the categories to which the component belongs.
-
@Icon: Defines the component family icon. This icon is visible in the Studio metadata tree.
Creating the internationalization file
Talend Component Kit supports internationalization (i18n) via Java properties files. Using these files, you can customize and translate the display name of properties such as the name of a component family or, as shown later in this tutorial, labels displayed in the component configuration.
Go to src/main/resources/org/talend/components/hazelcast and create an i18n Messages.properties file as below:
# An i18n name for the component family
Hazelcast._displayName=HazelcastProviding the family icon
You can define the component family icon in the package-info.java file. The icon image must exist in the resources/icons folder.
TCK supports both SVG and PNG formats for the icons.
-
Create the
iconsfolder and add an icon image for the Hazelcast family.$ mkdir -p src/main/resources/iconsThis tutorial uses the Hazelcast icon from the official GitHub repository that you can get from: avatars3.githubusercontent.com/u/1453152?s=200&v=4
-
Download the image and rename it to
Hazelcast_icon32.png. The name syntax is important and should match<Icon id from the package-info>_icon.32.png.
The component registration is now complete. The next step consists in defining the component configuration.
Defining the Hazelcast component configuration
All Input and Output (I/O) components follow a predefined model of configuration. The configuration requires two parts:
-
Datastore: Defines all properties that let the component connect to the targeted system.
-
Dataset: Defines the data to be read or written from/to the targeted system.
Datastore
Connecting to the Hazelcast cluster requires the IP address, group name and password of the targeted cluster.
In the component, the datastore is represented by a simple POJO.
-
Create a
HazelcastDatastore.javaclass file in thesrc/main/java/org/talend/components/hazelcastfolder.package org.talend.components.hazelcast; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.configuration.constraint.Required; import org.talend.sdk.component.api.configuration.type.DataStore; import org.talend.sdk.component.api.configuration.ui.layout.GridLayout; import org.talend.sdk.component.api.configuration.ui.widget.Credential; import org.talend.sdk.component.api.meta.Documentation; import java.io.Serializable; @GridLayout({ (1) @GridLayout.Row("clusterIpAddress"), @GridLayout.Row({"groupName", "password"}) }) @DataStore("HazelcastDatastore") (2) @Documentation("Hazelcast Datastore configuration") (3) public class HazelcastDatastore implements Serializable { @Option (4) @Required (5) @Documentation("The hazelcast cluster ip address") private String clusterIpAddress; @Option @Documentation("cluster group name") private String groupName; @Option @Credential (6) @Documentation("cluster password") private String password; // Getters & Setters omitted for simplicity // You need to generate them }1 @GridLayout: define the UI layout of this configuration in a grid manner.2 @DataStore: mark this POJO as being a data store with the idHazelcastDatastorethat can be used to reference the datastore in the i18n files or some services3 @Documentation: document classes and properties. then TCK rely on those metadata to generate a documentation for the component.4 @Option: mark class’s attributes as being a configuration entry.5 @Required: mark a configuration as being required.6 @Credential: mark an Option as being a sensible data that need to be encrypted before it’s stored. -
Define the i18n properties of the datastore. In the
Messages.propertiesfile let add the following lines:#datastore Hazelcast.datastore.HazelcastDatastore._displayName=Hazelcast Connection HazelcastDatastore.clusterIpAddress._displayName=Cluster ip address HazelcastDatastore.groupName._displayName=Group Name HazelcastDatastore.password._displayName=Password
The Hazelcast datastore is now defined.
Dataset
Hazelcast includes different types of datastores. You can manipulate maps, lists, sets, caches, locks, queues, topics and so on.
This tutorial focuses on maps but still applies to the other data structures.
Reading/writing from a map requires the map name.
-
Create the dataset class by creating a
HazelcastDataset.javafile insrc/main/java/org/talend/components/hazelcast.package org.talend.components.hazelcast; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.configuration.type.DataSet; import org.talend.sdk.component.api.configuration.ui.layout.GridLayout; import org.talend.sdk.component.api.meta.Documentation; import java.io.Serializable; @GridLayout({ @GridLayout.Row("connection"), @GridLayout.Row("mapName") }) @DataSet("HazelcastDataset") @Documentation("Hazelcast dataset") public class HazelcastDataset implements Serializable { @Option @Documentation("Hazelcast connection") private HazelcastDatastore connection; @Option @Documentation("Hazelcast map name") private String mapName; // Getters & Setters omitted for simplicity // You need to generate them }The
@Datasetannotation marks the class as a dataset. Note that it also references a datastore, as required by the components model. -
Just how it was done for the datastore, define the i18n properties of the dataset. To do that, add the following lines to the
Messages.propertiesfile.#dataset Hazelcast.dataset.HazelcastDataset._displayName=Hazelcast Map HazelcastDataset.connection._displayName=Connection HazelcastDataset.mapName._displayName=Map Name
The component configuration is now ready. The next step consists in creating the Source that will read the data from the Hazelcast map.
Source
The Source is the class responsible for reading the data from the configured dataset.
A source gets the configuration instance injected by TCK at runtime and uses it to connect to the targeted system and read the data.
-
Create a new class as follows.
package org.talend.components.hazelcast; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.IOException; import java.io.Serializable; @Version @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") (1) @Emitter(name = "Input") (2) @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration) { this.dataset = configuration; } @PostConstruct (3) public void init() throws IOException { //Here we can init connections } @Producer (4) public Record next() { // provide a record every time it is called. Returns null if there is no more data return null; } @PreDestroy (5) public void release() { // clean and release any resources } }1 The Iconannotation defines the icon of the component. Here, it uses the same icon as the family icon but you can use a different one.2 The class is annotated with @Emitter. It marks this class as being a source that will produce records.
The constructor of the source class lets TCK inject the required configuration to the source. We can also inject some common services provided by TCK or other services that we can define in the component. We will see the service part later in this tutorial.3 The method annotated with @PostConstructprepares resources or opens a connection, for example.4 The method annotated with @Producerretrieves the next record if any. The method will returnnullif no more record can be read.5 The method annotated with @PreDestroycleans any resource that was used or opened in the Source. -
The source also needs i18n properties to provide a readable display name. Add the following line to the
Messages.propertiesfile.#Source Hazelcast.Input._displayName=Input -
At this point, it is already possible to see the result in the Talend Component Web Tester to check how the configuration looks like and validate the layout visually. To do that, execute the following command in the project folder.
$ mvn clean install talend-component:webThis command starts the Component Web Tester and deploys the component there.
-
Access localhost:8080/.
[INFO] [INFO] --- talend-component-maven-plugin:1.1.12:web (default-cli) @ talend-component-hazelcast --- [16:46:52.361][INFO ][.WebServer_8080][oyote.http11.Http11NioProtocol] Initializing ProtocolHandler ["http-nio-8080"] [16:46:52.372][INFO ][.WebServer_8080][.catalina.core.StandardService] Starting service [Tomcat] [16:46:52.372][INFO ][.WebServer_8080][e.catalina.core.StandardEngine] Starting Servlet engine: [Apache Tomcat/9.0.22] [16:46:52.378][INFO ][.WebServer_8080][oyote.http11.Http11NioProtocol] Starting ProtocolHandler ["http-nio-8080"] [16:46:52.390][INFO ][.WebServer_8080][g.apache.meecrowave.Meecrowave] --------------- http://localhost:8080 ... [INFO] You can now access the UI at http://localhost:8080 [INFO] Enter 'exit' to quit [INFO] Initializing class org.talend.sdk.component.server.front.ComponentResourceImpl
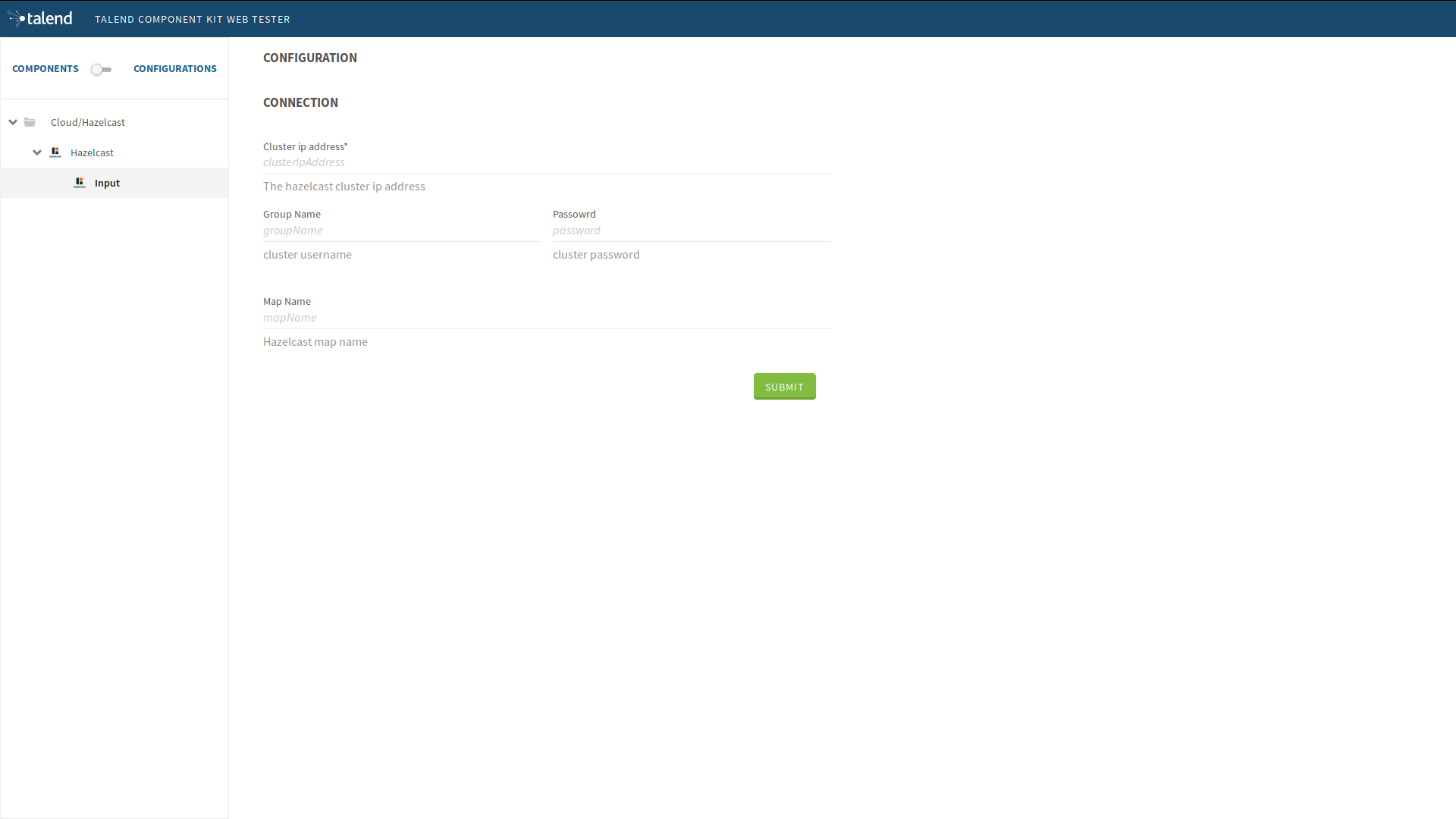
The source is set up. It is now time to start creating some Hazelcast specific code to connect to a cluster and read values for a map.
Source implementation for Hazelcast
-
Add the
hazelcast-clientMaven dependency to thepom.xmlof the project, in thedependenciesnode.<dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast-client</artifactId> <version>3.12.2</version> </dependency> -
Add a Hazelcast instance to the
@PostConstructmethod.-
Declare a
HazelcastInstanceattribute in the source class.Any non-serializable attribute needs to be marked as transient to avoid serialization issues. -
Implement the post construct method.
package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import static java.util.Collections.singletonList; @Version @Emitter(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration) { this.dataset = configuration; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Producer public Record next() { // Provides a record every time it is called. Returns null if there is no more data return null; } @PreDestroy public void release() { // Cleans and releases any resource } }The component configuration is mapped to the Hazelcast client configuration to create a Hazelcast instance. This instance will be used later to get the map from its name and read the map data. Only the required configuration in the component is exposed to keep the code as simple as possible.
-
-
Implement the code responsible for reading the data from the Hazelcast map through the
Producermethod.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.Iterator; import java.util.Map; import static java.util.Collections.singletonList; @Version @Emitter(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private transient Iterator<Map.Entry<String, String>> mapIterator; private final RecordBuilderFactory recordBuilderFactory; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Producer public Record next() { // Provides a record every time it is called. Returns null if there is no more data if (mapIterator == null) { // Gets the Distributed Map from Cluster. IMap<String, String> map = hazelcastInstance.getMap(dataset.getMapName()); mapIterator = map.entrySet().iterator(); } if (!mapIterator.hasNext()) { return null; } final Map.Entry<String, String> entry = mapIterator.next(); return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build(); } @PreDestroy public void release() { // Cleans and releases any resource } }The
Producerimplements the following logic:-
Check if the map iterator is already initialized. If not, get the map from its name and initialize the map iterator. This is done in the
@Producermethod to ensure the map is initialized only if thenext()method is called (lazy initialization). It also avoids the map initialization in thePostConstructmethod as the Hazelcast map is not serializable.All the objects initialized in the PostConstructmethod need to be serializable as the source can be serialized and sent to another worker in a distributed cluster. -
From the map, create an iterator on the map keys that will read from the map.
-
Transform every key/value pair into a Talend Record with a "key, value" object on every call to
next().The RecordBuilderFactoryclass used above is a built-in service in TCK injected via the Source constructor. This service is a factory to create Talend Records. -
Now, the
next()method will produce a Record every time it is called. The method will return "null" if there is no more data in the map.
-
-
Implement the
@PreDestroyannotated method, responsible for releasing all resources used by the Source. The method needs to shut the Hazelcast client instance down to release any connection between the component and the Hazelcast cluster.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.Iterator; import java.util.Map; import static java.util.Collections.singletonList; @Version @Emitter(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private transient Iterator<Map.Entry<String, String>> mapIterator; private final RecordBuilderFactory recordBuilderFactory; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Producer public Record next() { // Provides a record every time it is called. Returns null if there is no more data if (mapIterator == null) { // Get the Distributed Map from Cluster. IMap<String, String> map = hazelcastInstance.getMap(dataset.getMapName()); mapIterator = map.entrySet().iterator(); } if (!mapIterator.hasNext()) { return null; } final Map.Entry<String, String> entry = mapIterator.next(); return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build(); } @PreDestroy public void release() { // Clean and release any resource if (hazelcastInstance != null) { hazelcastInstance.shutdown(); } } }
The Hazelcast Source is completed. The next section shows how to write a simple unit test to check that it works properly.
Testing the Source
TCK provides a set of APIs and tools that makes the testing straightforward.
The test of the Hazelcast Source consists in creating an embedded Hazelcast instance with only one member and initializing it with some data, and then in creating a test Job to read the data from it using the implemented Source.
-
Add the required Maven test dependencies to the project.
<dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter</artifactId> <version>5.5.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.talend.sdk.component</groupId> <artifactId>component-runtime-junit</artifactId> <version>1.1.12</version> <scope>test</scope> </dependency> -
Initialize a Hazelcast test instance and create a map with some test data. To do that, create the
HazelcastSourceTest.javatest class in thesrc/test/javafolder. Create the folder if it does not exist.package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import static org.junit.jupiter.api.Assertions.assertEquals; class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static HazelcastInstance hazelcastInstance; @BeforeAll static void init() { hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); } @Test void initTest() { IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); assertEquals(4, map.size()); } @AfterAll static void shutdown() { hazelcastInstance.shutdown(); } }The above example creates a Hazelcast instance for the test and creates the
MY-DISTRIBUTED-MAPmap. ThegetMapcreates the map if it does not already exist. Some keys and values uses in the test are added. Then, a simple test checks that the data is correctly initialized. Finally, the Hazelcast test instance is shut down. -
Run the test and check in the logs that a Hazelcast cluster of one member has been created and that the test has passed.
$ mvn clean test -
To be able to test components, TCK provides the
@WithComponentsannotation which enables component testing. Add this annotation to the test. The annotation takes the component Java package as a value parameter.package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.talend.sdk.component.junit5.WithComponents; import static org.junit.jupiter.api.Assertions.assertEquals; @WithComponents("org.talend.components.hazelcast") class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static HazelcastInstance hazelcastInstance; @BeforeAll static void init() { hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); } @Test void initTest() { IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); assertEquals(4, map.size()); } @AfterAll static void shutdown() { hazelcastInstance.shutdown(); } } -
Create the test Job that configures the Hazelcast instance and link it to an output that collects the data produced by the Source.
package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.junit.BaseComponentsHandler; import org.talend.sdk.component.junit5.Injected; import org.talend.sdk.component.junit5.WithComponents; import org.talend.sdk.component.runtime.manager.chain.Job; import java.util.List; import static org.junit.jupiter.api.Assertions.assertEquals; import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample; @WithComponents("org.talend.components.hazelcast") class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static HazelcastInstance hazelcastInstance; @Injected protected BaseComponentsHandler componentsHandler; (1) @BeforeAll static void init() { hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); } @Test void initTest() { IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); assertEquals(4, map.size()); } @Test void sourceTest() { (2) final HazelcastDatastore connection = new HazelcastDatastore(); connection.setClusterIpAddress(hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost()); connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName()); connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword()); final HazelcastDataset dataset = new HazelcastDataset(); dataset.setConnection(connection); dataset.setMapName(MAP_NAME); final String configUri = configurationByExample().forInstance(dataset).configured().toQueryString(); (3) Job.components() .component("Input", "Hazelcast://Input?" + configUri) .component("Output", "test://collector") .connections() .from("Input").to("Output") .build() .run(); List<Record> data = componentsHandler.getCollectedData(Record.class); assertEquals(4, data.size()); (4) } @AfterAll static void shutdown() { hazelcastInstance.shutdown(); } }1 The componentsHandlerattribute is injected to the test by TCK. This component handler gives access to the collected data.2 The sourceTestmethod instantiates the configuration of the Source and fills it with the configuration of the Hazelcast test instance created before to let the Source connect to it.
The Job API provides a simple way to build a DAG (Directed Acyclic Graph) Job using Talend components and then runs it on a specific runner (standalone, Beam or Spark). This test starts using the default runner only, which is the standalone one.3 The configurationByExample()method creates theByExamplefactory. It provides a simple way to convert the configuration instance to an URI configuration used with the Job API to configure the component.4 The job runs and checks that the collected data size is equal to the initialized test data. -
Execute the unit test and check that it passes, meaning that the Source is reading the data correctly from Hazelcast.
$ mvn clean test
The Source is now completed and tested. The next section shows how to implement the Partition Mapper for the Source. In this case, the Partition Mapper will split the work (data reading) between the available cluster members to distribute the workload.
Partition Mapper
The Partition Mapper calculates the number of Sources that can be created and executed in parallel on the available workers of a distributed system. For Hazelcast, it corresponds to the cluster member count.
To fully illustrate this concept, this section also shows how to enhance the test environment to add more Hazelcast cluster members and initialize it with more data.
-
Instantiate more Hazelcast instances, as every Hazelcast instance corresponds to one member in a cluster. In the test, it is reflected as follows:
package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.junit.BaseComponentsHandler; import org.talend.sdk.component.junit5.Injected; import org.talend.sdk.component.junit5.WithComponents; import org.talend.sdk.component.runtime.manager.chain.Job; import java.util.List; import java.util.UUID; import java.util.stream.Collectors; import java.util.stream.IntStream; import static org.junit.jupiter.api.Assertions.assertEquals; import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample; @WithComponents("org.talend.components.hazelcast") class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static final int CLUSTER_MEMBERS_COUNT = 2; private static final int MAX_DATA_COUNT_BY_MEMBER = 50; private static List<HazelcastInstance> hazelcastInstances; @Injected protected BaseComponentsHandler componentsHandler; @BeforeAll static void init() { hazelcastInstances = IntStream.range(0, CLUSTER_MEMBERS_COUNT) .mapToObj(i -> Hazelcast.newHazelcastInstance()) .collect(Collectors.toList()); //add some data hazelcastInstances.forEach(hz -> { final IMap<String, String> map = hz.getMap(MAP_NAME); IntStream.range(0, MAX_DATA_COUNT_BY_MEMBER) .forEach(i -> map.put(UUID.randomUUID().toString(), "value " + i)); }); } @Test void initTest() { IMap<String, String> map = hazelcastInstances.get(0).getMap(MAP_NAME); assertEquals(CLUSTER_MEMBERS_COUNT * MAX_DATA_COUNT_BY_MEMBER, map.size()); } @Test void sourceTest() { final HazelcastDatastore connection = new HazelcastDatastore(); HazelcastInstance hazelcastInstance = hazelcastInstances.get(0); connection.setClusterIpAddress( hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost()); connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName()); connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword()); final HazelcastDataset dataset = new HazelcastDataset(); dataset.setConnection(connection); dataset.setMapName(MAP_NAME); final String configUri = configurationByExample().forInstance(dataset).configured().toQueryString(); Job.components() .component("Input", "Hazelcast://Input?" + configUri) .component("Output", "test://collector") .connections() .from("Input") .to("Output") .build() .run(); List<Record> data = componentsHandler.getCollectedData(Record.class); assertEquals(CLUSTER_MEMBERS_COUNT * MAX_DATA_COUNT_BY_MEMBER, data.size()); } @AfterAll static void shutdown() { hazelcastInstances.forEach(HazelcastInstance::shutdown); } }The above code sample creates two Hazelcast instances, leading to the creation of two Hazelcast members. Having a cluster of two members (nodes) will allow to distribute the data.
The above code also adds more data to the test map and updates the shutdown method and the test. -
Run the test on the multi-nodes cluster.
mvn clean testThe Source is a simple implementation that does not distribute the workload and reads the data in a classic way, without distributing the read action to different cluster members. -
Start implementing the Partition Mapper class by creating a
HazelcastPartitionMapper.javaclass file.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.util.List; import java.util.UUID; import static java.util.Collections.singletonList; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private final RecordBuilderFactory recordBuilderFactory; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName()+"-"+ UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Assessor public long estimateSize() { return 0; } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { return null; } @Emitter public HazelcastSource createSource() { return null; } @PreDestroy public void release() { if(hazelcastInstance != null) { hazelcastInstance.shutdown(); } } }When coupling a Partition Mapper with a Source, the Partition Mapper becomes responsible for injecting parameters and creating source instances. This way, all the attribute initialization part moves from the Source to the Partition Mapper class.
The configuration also sets an instance name to make it easy to find the client instance in the logs or while debugging.
The Partition Mapper class is composed of the following:
-
constructor: Handles configuration and service injections -
Assessor: This annotation indicates that the method is responsible for assessing the dataset size. The underlying runner uses the estimated dataset size to compute the optimal bundle size to distribute the workload efficiently. -
Split: This annotation indicates that the method is responsible for creating Partition Mapper instances based on the bundle size requested by the underlying runner and the size of the dataset. It creates as much partitions as possible to parallelize and distribute the workload efficiently on the available workers (known as members in the Hazelcast case). -
Emitter: This annotation indicates that the method is responsible for creating the Source instance with an adapted configuration allowing to handle the amount of records it will produce and the required services.
I adapts the configuration to let the Source read only the requested bundle of data.
-
Assessor
The Assessor method computes the memory size of every member of the cluster. Implementing it requires submitting a calculation task to the members through a serializable task that is aware of the Hazelcast instance.
-
Create the serializable task.
package org.talend.components.hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.HazelcastInstanceAware; import java.io.Serializable; import java.util.concurrent.Callable; public abstract class SerializableTask<T> implements Callable<T>, Serializable, HazelcastInstanceAware { protected transient HazelcastInstance localInstance; @Override public void setHazelcastInstance(final HazelcastInstance hazelcastInstance) { localInstance = hazelcastInstance; } }The purpose of this class is to submit any task to the Hazelcast cluster.
-
Use the created task to estimate the dataset size in the
Assessormethod.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IExecutorService; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.util.List; import java.util.UUID; import java.util.concurrent.ExecutionException; import static java.util.Collections.singletonList; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private final RecordBuilderFactory recordBuilderFactory; private transient IExecutorService executorService; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName()+"-"+ UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Assessor public long estimateSize() { return getExecutorService().submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }).values().stream().mapToLong(feature -> { try { return feature.get(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }).sum(); } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { return null; } @Emitter public HazelcastSource createSource() { return null; } @PreDestroy public void release() { if(hazelcastInstance != null) { hazelcastInstance.shutdown(); } } private IExecutorService getExecutorService() { return executorService == null ? executorService = hazelcastInstance.getExecutorService("talend-executor-service") : executorService; } }The
Assessormethod calculates the memory size that the map occupies for all members.
In Hazelcast, distributing a task to all members can be achieved using an execution service initialized in thegetExecutorService()method. The size of the map is requested on every available member. By summing up the results, the total size of the map in the distributed cluster is computed.
Split
The Split method calculates the heap size of the map on every member of the cluster.
Then, it calculates how many members a source can handle.
If a member contains less data than the requested bundle size, the method tries to combine it with another member. That combination can only happen if the combined data size is still less or equal to the requested bundle size.
The following code illustrates the logic described above.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IExecutorService;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import static java.util.Collections.singletonList;
import static java.util.Collections.synchronizedMap;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.toMap;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private final RecordBuilderFactory recordBuilderFactory;
private transient IExecutorService executorService;
private List<String> members;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
private HazelcastPartitionMapper(final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = membersUUID;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Assessor
public long estimateSize() {
return executorService.submitToAllMembers(
() -> hazelcastInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost())
.values()
.stream()
.mapToLong(feature -> {
try {
return feature.get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
})
.sum();
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
final Map<String, Long> heapSizeByMember =
getExecutorService().submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
}).entrySet().stream().map(heapSizeMember -> {
try {
return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(),
heapSizeMember.getValue().get());
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}).collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue));
final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream()
.map(e -> combineMembers(e, bundleSize, heapSizeByMember))
.filter(Objects::nonNull)
.map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m))
.collect(toList());
if (partitions.isEmpty()) {
List<String> allMembers =
hazelcastInstance.getCluster().getMembers().stream().map(Member::getUuid).collect(toList());
partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers));
}
return partitions;
}
private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) {
if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) {
return null;
}
final List<String> combined = new ArrayList<>();
long size = sizeByMember.remove(current);
combined.add(current);
for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Long> entry = it.next();
if (size + entry.getValue() <= bundleSize) {
combined.add(entry.getKey());
size += entry.getValue();
it.remove();
}
}
return combined;
}
@Emitter
public HazelcastSource createSource() {
return null;
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
private IExecutorService getExecutorService() {
return executorService == null ?
executorService = hazelcastInstance.getExecutorService("talend-executor-service") :
executorService;
}
}The next step consists in adapting the source to take the Split into account.
Source
The following sample shows how to adapt the Source to the Split carried out previously.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import static java.util.Collections.singletonList;
import static java.util.stream.Collectors.toMap;
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
private transient HazelcastInstance hazelcastInstance;
private final List<String> members;
private transient Iterator<Map.Entry<String, String>> mapIterator;
private final RecordBuilderFactory recordBuilderFactory;
private transient Iterator<Map.Entry<Member, Future<Map<String, String>>>> dataByMember;
public HazelcastSource(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory,
final List<String> members) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = members;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Producer
public Record next() {
if (dataByMember == null) {
dataByMember = hazelcastInstance.getExecutorService("talend-source")
.submitToMembers(new SerializableTask<Map<String, String>>() {
@Override
public Map<String, String> call() {
final IMap<String, String> map = localInstance.getMap(dataset.getMapName());
final Set<String> localKeySet = map.localKeySet();
return localKeySet.stream().collect(toMap(k -> k, map::get));
}
}, member -> members.contains(member.getUuid()))
.entrySet()
.iterator();
}
if (mapIterator != null && !mapIterator.hasNext() && !dataByMember.hasNext()) {
return null;
}
if (mapIterator == null || !mapIterator.hasNext()) {
Map.Entry<Member, Future<Map<String, String>>> next = dataByMember.next();
try {
mapIterator = next.getValue().get().entrySet().iterator();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
Map.Entry<String, String> entry = mapIterator.next();
return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build();
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
}The next method reads the data from the members received from the Partition Mapper.
A Big Data runner like Spark will get multiple Source instances. Every source instance will be responsible for reading data from a specific set of members already calculated by the Partition Mapper.
The data is fetched only when the next method is called. This logic allows to stream the data from members without loading it
all into the memory.
Emitter
-
Implement the method annotated with
@Emitterin theHazelcastPartitionMapperclass.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IExecutorService; import com.hazelcast.core.Member; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.AbstractMap; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Objects; import java.util.UUID; import java.util.concurrent.ExecutionException; import static java.util.Collections.singletonList; import static java.util.stream.Collectors.toList; import static java.util.stream.Collectors.toMap; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private final RecordBuilderFactory recordBuilderFactory; private transient IExecutorService executorService; private List<String> members; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } private HazelcastPartitionMapper(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.members = membersUUID; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Assessor public long estimateSize() { return getExecutorService().submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }).values().stream().mapToLong(feature -> { try { return feature.get(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }).sum(); } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { final Map<String, Long> heapSizeByMember = getExecutorService().submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }).entrySet().stream().map(heapSizeMember -> { try { return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(), heapSizeMember.getValue().get()); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }).collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue)); final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream() .map(e -> combineMembers(e, bundleSize, heapSizeByMember)) .filter(Objects::nonNull) .map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m)) .collect(toList()); if (partitions.isEmpty()) { List<String> allMembers = hazelcastInstance.getCluster().getMembers().stream().map(Member::getUuid).collect(toList()); partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers)); } return partitions; } private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) { if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) { return null; } final List<String> combined = new ArrayList<>(); long size = sizeByMember.remove(current); combined.add(current); for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) { Map.Entry<String, Long> entry = it.next(); if (size + entry.getValue() <= bundleSize) { combined.add(entry.getKey()); size += entry.getValue(); it.remove(); } } return combined; } @Emitter public HazelcastSource createSource() { return new HazelcastSource(dataset, recordBuilderFactory, members); } @PreDestroy public void release() { if (hazelcastInstance != null) { hazelcastInstance.shutdown(); } } private IExecutorService getExecutorService() { return executorService == null ? executorService = hazelcastInstance.getExecutorService("talend-executor-service") : executorService; } }The
createSource()method creates the source instance and passes the required services and the selected Hazelcast members to the source instance. -
Run the test and check that it works as intended.
$ mvn clean testThe component implementation is now done. It is able to read data and to distribute the workload to available members in a Big Data execution environment.
Introducing TCK services
Refactor the component by introducing a service to make some pieces of code reusable and avoid code duplication.
-
Refactor the Hazelcast instance creation into a service.
package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IExecutorService; import org.talend.sdk.component.api.service.Service; import java.io.Serializable; import java.util.UUID; import static java.util.Collections.singletonList; @Service public class HazelcastService implements Serializable { private transient HazelcastInstance hazelcastInstance; private transient IExecutorService executorService; public HazelcastInstance getOrCreateIntance(final HazelcastDatastore connection) { if (hazelcastInstance == null || !hazelcastInstance.getLifecycleService().isRunning()) { final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } return hazelcastInstance; } public void shutdownInstance() { if (hazelcastInstance != null) { hazelcastInstance.shutdown(); } } public IExecutorService getExecutorService(final HazelcastDatastore connection) { return executorService == null ? executorService = getOrCreateIntance(connection).getExecutorService("talend-executor-service") : executorService; } } -
Inject this service to the Partition Mapper to reuse it.
package org.talend.components.hazelcast; import com.hazelcast.core.IExecutorService; import com.hazelcast.core.Member; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.AbstractMap; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Objects; import java.util.concurrent.ExecutionException; import static java.util.stream.Collectors.toList; import static java.util.stream.Collectors.toMap; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper implements Serializable { private final HazelcastDataset dataset; private final RecordBuilderFactory recordBuilderFactory; private transient IExecutorService executorService; private List<String> members; private final HazelcastService hazelcastService; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, final HazelcastService hazelcastService) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.hazelcastService = hazelcastService; } private HazelcastPartitionMapper(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID, final HazelcastService hazelcastService) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.hazelcastService = hazelcastService; this.members = membersUUID; } @PostConstruct public void init() { // We initialize the hazelcast instance only on it first usage now } @Assessor public long estimateSize() { return hazelcastService.getExecutorService(dataset.getConnection()) .submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }) .values() .stream() .mapToLong(feature -> { try { return feature.get(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }) .sum(); } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { final Map<String, Long> heapSizeByMember = hazelcastService.getExecutorService(dataset.getConnection()) .submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }) .entrySet() .stream() .map(heapSizeMember -> { try { return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(), heapSizeMember.getValue().get()); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }) .collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue)); final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream() .map(e -> combineMembers(e, bundleSize, heapSizeByMember)) .filter(Objects::nonNull) .map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m, hazelcastService)) .collect(toList()); if (partitions.isEmpty()) { List<String> allMembers = hazelcastService.getOrCreateIntance(dataset.getConnection()) .getCluster() .getMembers() .stream() .map(Member::getUuid) .collect(toList()); partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers, hazelcastService)); } return partitions; } private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) { if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) { return null; } final List<String> combined = new ArrayList<>(); long size = sizeByMember.remove(current); combined.add(current); for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) { Map.Entry<String, Long> entry = it.next(); if (size + entry.getValue() <= bundleSize) { combined.add(entry.getKey()); size += entry.getValue(); it.remove(); } } return combined; } @Emitter public HazelcastSource createSource() { return new HazelcastSource(dataset, recordBuilderFactory, members, hazelcastService); } @PreDestroy public void release() { hazelcastService.shutdownInstance(); } } -
Adapt the Source class to reuse the service.
package org.talend.components.hazelcast; import com.hazelcast.core.IMap; import com.hazelcast.core.Member; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Set; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; import static java.util.stream.Collectors.toMap; public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; private final List<String> members; private transient Iterator<Map.Entry<String, String>> mapIterator; private final RecordBuilderFactory recordBuilderFactory; private transient Iterator<Map.Entry<Member, Future<Map<String, String>>>> dataByMember; private final HazelcastService hazelcastService; public HazelcastSource(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, final List<String> members, final HazelcastService hazelcastService) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.members = members; this.hazelcastService = hazelcastService; } @PostConstruct public void init() { // We initialize the hazelcast instance only on it first usage now } @Producer public Record next() { if (dataByMember == null) { dataByMember = hazelcastService.getOrCreateIntance(dataset.getConnection()) .getExecutorService("talend-source") .submitToMembers(new SerializableTask<Map<String, String>>() { @Override public Map<String, String> call() { final IMap<String, String> map = localInstance.getMap(dataset.getMapName()); final Set<String> localKeySet = map.localKeySet(); return localKeySet.stream().collect(toMap(k -> k, map::get)); } }, member -> members.contains(member.getUuid())) .entrySet() .iterator(); } if (mapIterator != null && !mapIterator.hasNext() && !dataByMember.hasNext()) { return null; } if (mapIterator == null || !mapIterator.hasNext()) { Map.Entry<Member, Future<Map<String, String>>> next = dataByMember.next(); try { mapIterator = next.getValue().get().entrySet().iterator(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } } Map.Entry<String, String> entry = mapIterator.next(); return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build(); } @PreDestroy public void release() { hazelcastService.shutdownInstance(); } } -
Run the test one last time to ensure everything still works as expected.
Thank you for following this tutorial. Use the logic and approach presented here to create any input component for any system.
Implementing an Output component for Hazelcast
| This tutorial is the continuation of Talend Input component for Hazelcast tutorial. We will not walk through the project creation again, So please start from there before taking this one. |
This tutorial shows how to create a complete working output component for Hazelcast
Defining the configurable part and the layout of the component
As seen before, in Hazelcast there is multiple data source type. You can find queues, topics, cache, maps…
In this tutorials we will stick with the Map dataset and all what we will see here is applicable to the other types.
Let’s assume that our Hazelcast output component will be responsible of inserting data into a distributed Map. For that, we will need to know which attribute from the incoming data is to be used as a key in the map. The value will be the hole record encoded into a json format.
Bu that in mind, we can design our output configuration as: the same Datastore and Dataset from the input component and an additional configuration that will define the key attribute.
Let’s create our Output configuration class.
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.configuration.ui.layout.GridLayout;
import org.talend.sdk.component.api.meta.Documentation;import java.io.Serializable;
@GridLayout({
@GridLayout.Row("dataset"),
@GridLayout.Row("key")
})
@Documentation("Hazelcast output configuration")
public class HazelcastOutputConfig implements Serializable {
@Option
@Documentation("the hazelcast dataset")
private HazelcastDataset dataset;
@Option
@Documentation("The key attribute")
private String key;
// Getters & Setters omitted for simplicity
// You need to generate them
}Let’s add the i18n properties of our configuration into the Messages.properties file
# Output config
HazelcastOutputConfig.dataset._displayName=Hazelcast dataset
HazelcastOutputConfig.key._displayName=Key attributeOutput Implementation
The skeleton of the output component looks as follows:
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.processor.Processor;
import org.talend.sdk.component.api.record.Record;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import static org.talend.sdk.component.api.component.Icon.IconType.CUSTOM;
@Version
@Icon(custom = "Hazelcast", value = CUSTOM)
@Processor(name = "Output")
@Documentation("Hazelcast output component")
public class HazelcastOutput implements Serializable {
public HazelcastOutput(@Option("configuration") final HazelcastOutputConfig configuration) {
}
@PostConstruct
public void init() {
}
@PreDestroy
public void release() {
}
@ElementListener
public void onElement(final Record record) {
}
}-
@Versionannotation indicates the version of the component. It is used to migrate the component configuration if needed. -
@Iconannotation indicates the icon of the component. Here, the icon is a custom icon that needs to be bundled in the component JAR underresources/icons. -
@Processorannotation indicates that this class is the processor (output) and defines the name of the component. -
constructorof the processor is responsible for injecting the component configuration and services. Configuration parameters are annotated with@Option. The other parameters are considered as services and are injected by the component framework. Services can be local (class annotated with@Service) or provided by the component framework. -
The method annotated with
@PostConstructis executed once by instance and can be used for initialization. -
The method annotated with
@PreDestroyis used to clean resources at the end of the execution of the output. -
Data is passed to the method annotated with
@ElementListener. That method is responsible for handling the data output. You can define all the related logic in this method.
| If you need to bulk write the updates accordingly to groups, see Processors and batch processing. |
Now, we will need to add the display name of the Output to the i18n resources file Messages.properties
#Output
Hazelcast.Output._displayName=OutputLet’s implement all of those methods
Defining the constructor method
We will create the outpu contructor to inject the component configuration and some additional local and built in services.
| Built in services are services provided by TCK. |
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.processor.Processor;
import org.talend.sdk.component.api.record.Record;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import javax.json.bind.Jsonb;
import java.io.Serializable;
import static org.talend.sdk.component.api.component.Icon.IconType.CUSTOM;
@Version
@Icon(custom = "Hazelcast", value = CUSTOM)
@Processor(name = "Output")
@Documentation("Hazelcast output component")
public class HazelcastOutput implements Serializable {
private final HazelcastOutputConfig configuration;
private final HazelcastService hazelcastService;
private final Jsonb jsonb;
public HazelcastOutput(@Option("configuration") final HazelcastOutputConfig configuration,
final HazelcastService hazelcastService, final Jsonb jsonb) {
this.configuration = configuration;
this.hazelcastService = hazelcastService;
this.jsonb = jsonb;
}
@PostConstruct
public void init() {
}
@PreDestroy
public void release() {
}
@ElementListener
public void onElement(final Record record) {
}
}Here we find:
-
configurationis the component configuration class -
hazelcastServiceis the service that we have implemented in the input component tutorial. it will be responsible of creating a hazelcast client instance. -
jsonbis a built in service provided by tck to handle json object serialization and deserialization. We will use it to convert the incoming record to json format before inseting them into the map.
Defining the PostConstruct method
Nothing to do in the post construct method. but we could for example initialize a hazle cast instance there. but we will
do it in a lazy way on the first call in the @ElementListener method
Defining the PreDestroy method
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.processor.Processor;
import org.talend.sdk.component.api.record.Record;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import javax.json.bind.Jsonb;
import java.io.Serializable;
import static org.talend.sdk.component.api.component.Icon.IconType.CUSTOM;
@Version
@Icon(custom = "Hazelcast", value = CUSTOM)
@Processor(name = "Output")
@Documentation("Hazelcast output component")
public class HazelcastOutput implements Serializable {
private final HazelcastOutputConfig configuration;
private final HazelcastService hazelcastService;
private final Jsonb jsonb;
public HazelcastOutput(@Option("configuration") final HazelcastOutputConfig configuration,
final HazelcastService hazelcastService, final Jsonb jsonb) {
this.configuration = configuration;
this.hazelcastService = hazelcastService;
this.jsonb = jsonb;
}
@PostConstruct
public void init() {
//no-op
}
@PreDestroy
public void release() {
this.hazelcastService.shutdownInstance();
}
@ElementListener
public void onElement(final Record record) {
}
}Shut down the Hazelcast client instance and thus free the Hazelcast map reference.
Defining the ElementListener method
package org.talend.components.hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.processor.Processor;
import org.talend.sdk.component.api.record.Record;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import javax.json.bind.Jsonb;
import java.io.Serializable;
import static org.talend.sdk.component.api.component.Icon.IconType.CUSTOM;
@Version
@Icon(custom = "Hazelcast", value = CUSTOM)
@Processor(name = "Output")
@Documentation("Hazelcast output component")
public class HazelcastOutput implements Serializable {
private final HazelcastOutputConfig configuration;
private final HazelcastService hazelcastService;
private final Jsonb jsonb;
public HazelcastOutput(@Option("configuration") final HazelcastOutputConfig configuration,
final HazelcastService hazelcastService, final Jsonb jsonb) {
this.configuration = configuration;
this.hazelcastService = hazelcastService;
this.jsonb = jsonb;
}
@PostConstruct
public void init() {
//no-op
}
@PreDestroy
public void release() {
this.hazelcastService.shutdownInstance();
}
@ElementListener
public void onElement(final Record record) {
final String key = record.getString(configuration.getKey());
final String value = jsonb.toJson(record);
final HazelcastInstance hz = hazelcastService.getOrCreateIntance(configuration.getDataset().getConnection());
final IMap<String, String> map = hz.getMap(configuration.getDataset().getMapName());
map.put(key, value);
}
}We get the key attribute from the incoming record and then convert the hole record to a json string. Then we insert the key/value into the hazelcast map.
Testing the output component
Let’s create a unit test for our output component. The idea will be to create a job that will insert the data using this output implementation.
So, let’s create out test class.
package org.talend.components.hazelcast;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.talend.sdk.component.junit.BaseComponentsHandler;
import org.talend.sdk.component.junit5.Injected;
import org.talend.sdk.component.junit5.WithComponents;
@WithComponents("org.talend.components.hazelcast")
class HazelcastOuputTest {
private static final String MAP_NAME = "MY-DISTRIBUTED-MAP";
private static HazelcastInstance hazelcastInstance;
@Injected
protected BaseComponentsHandler componentsHandler;
@BeforeAll
static void init() {
hazelcastInstance = Hazelcast.newHazelcastInstance();
//init the map
final IMap<String, String> map = hazelcastInstances.getMap(MAP_NAME);
}
@AfterAll
static void shutdown() {
hazelcastInstance.shutdown();
}
}Here we start by creating a hazelcast test instance, and we initialize the map. we also shutdown the instance after all the test are executed.
Now let’s create our output test.
package org.talend.components.hazelcast;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.Service;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import org.talend.sdk.component.junit.BaseComponentsHandler;
import org.talend.sdk.component.junit5.Injected;
import org.talend.sdk.component.junit5.WithComponents;
import org.talend.sdk.component.runtime.manager.chain.Job;
import java.util.List;
import java.util.UUID;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample;
@WithComponents("org.talend.components.hazelcast")
class HazelcastOuputTest {
private static final String MAP_NAME = "MY-DISTRIBUTED-MAP";
private static HazelcastInstance hazelcastInstance;
@Injected
protected BaseComponentsHandler componentsHandler;
@Service
protected RecordBuilderFactory recordBuilderFactory;
@BeforeAll
static void init() {
hazelcastInstance = Hazelcast.newHazelcastInstance();
//init the map
final IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
}
@Test
void outputTest() {
final HazelcastDatastore connection = new HazelcastDatastore();
connection.setClusterIpAddress(
hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost());
connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName());
connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword());
final HazelcastDataset dataset = new HazelcastDataset();
dataset.setConnection(connection);
dataset.setMapName(MAP_NAME);
HazelcastOutputConfig config = new HazelcastOutputConfig();
config.setDataset(dataset);
config.setKey("id");
final String configUri = configurationByExample().forInstance(config).configured().toQueryString();
componentsHandler.setInputData(generateTestData(10));
Job.components()
.component("Input", "test://emitter")
.component("Output", "Hazelcast://Output?" + configUri)
.connections()
.from("Input")
.to("Output")
.build()
.run();
final IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
assertEquals(10, map.size());
}
private List<Record> generateTestData(int count) {
return IntStream.range(0, count)
.mapToObj(i -> recordBuilderFactory.newRecordBuilder()
.withString("id", UUID.randomUUID().toString())
.withString("val1", UUID.randomUUID().toString())
.withString("val2", UUID.randomUUID().toString())
.build())
.collect(Collectors.toList());
}
@AfterAll
static void shutdown() {
hazelcastInstance.shutdown();
}
}Here we start preparing the emitter test component provided bt TCK that we use in our test job
to generate random data for our output. Then, we use the output component to fill the hazelcast map.
By the end we test that the map contains the exact amount of data inserted by the job.
Run the test and check that it’s working.
$ mvn clean testCongratulation you just finished your output component.
Creating components for a REST API
This tutorial shows how to create components that consume a REST API.
The component developed as example in this tutorial is an input component that provides a search functionality for Zendesk using its Search API.
Lombok is used to avoid writing getter, setter and constructor methods.
You can generate a project using the Talend Components Kit starter, as described in this tutorial.
Setting up the HTTP client
The input component relies on Zendesk Search API and requires an HTTP client to consume it.
The Zendesk Search API takes the following parameters on the /api/v2/search.json endpoint.
-
query : The search query.
-
sort_by : The sorting type of the query result. Possible values are
updated_at,created_at,priority,status,ticket_type, orrelevance. It defaults torelevance. -
sort_order: The sorting order of the query result. Possible values are
asc(for ascending) ordesc(for descending). It defaults todesc.
Talend Component Kit provides a built-in service to create an easy-to-use HTTP client in a declarative manner, using Java annotations.
public interface SearchClient extends HttpClient { (1)
@Request(path = "api/v2/search.json", method = "GET") (2)
Response<JsonObject> search(@Header("Authorization") String auth,(3) (4)
@Query("query") String query, (5)
@Query("sort_by") String sortBy,
@Query("sort_order") String sortOrder,
@Query("page") Integer page
);
}| 1 | The interface needs to extend org.talend.sdk.component.api.service.http.HttpClient to be recognized as an HTTP client by the component framework.
This interface also provides the void base(String base) method, that allows to set the base URI for the HTTP request. In this tutorial, it is the Zendesk instance URL. |
| 2 | The @Request annotation allows to define the HTTP request path and method (GET, POST, PUT, and so on). |
| 3 | The method return type and a header parameter are defined. The method return type is a JSON object: Response<JsonObject>. The Response object allows to access the HTTP response status code, headers, error payload and the response body that are of the JsonObject type in this case.The response body is decoded according to the content type returned by the API. The component framework provides the codec to decode JSON content. If you want to consume specific content types, you need to specify your custom codec using the @Codec annotation. |
| 4 | The Authorization HTTP request header allows to provide the authorization token. |
| 5 | Query parameters are defined using the @Query annotation that provides the parameter name. |
No additional implementation is needed for the interface, as it is provided by the component framework, according to what is defined above.
| This HTTP client can be injected into a mapper or a processor to perform HTTP requests. |
Configuring the component
This example uses the basic authentication that supported by the API.
Configuring basic authentication
The first step is to set up the configuration for the basic authentication. To be able to consume the Search API, the Zendesk instance URL, the username and the password are needed.
@Data
@DataStore (1)
@GridLayout({ (2)
@GridLayout.Row({ "url" }),
@GridLayout.Row({ "username", "password" })
})
@Documentation("Basic authentication for Zendesk API")
public class BasicAuth {
@Option
@Documentation("Zendesk instance url")
private final String url;
@Option
@Documentation("Zendesk account username (e-mail).")
private final String username;
@Option
@Credential (3)
@Documentation("Zendesk account password")
private final String password;
public String getAuthorizationHeader() { (4)
try {
return "Basic " + Base64.getEncoder()
.encodeToString((this.getUsername() + ":" + this.getPassword()).getBytes("UTF-8"));
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
}
}| 1 | This configuration class provides the authentication information. Type it as Datastore so that it can be validated using services (similar to connection test) and used by Talend Studio or web application metadata. |
| 2 | @GridLayout defines the UI layout of this configuration. |
| 3 | The password is marked as Credential so that it is handled as sensitive data in Talend Studio and web applications. Read more about sensitive data handling. |
| 4 | This method generates a basic authentication token using the username and the password. This token is used to authenticate the HTTP call on the Search API. |
The data store is now configured. It provides a basic authentication token.
Configuring the dataset
Once the data store is configured, you can define the dataset by configuring the search query. It is that query that defines the records processed by the input component.
@Data
@DataSet (1)
@GridLayout({ (2)
@GridLayout.Row({ "dataStore" }),
@GridLayout.Row({ "query" }),
@GridLayout.Row({ "sortBy", "sortOrder" })
})
@Documentation("Data set that defines a search query for Zendesk Search API. See API reference https://developer.zendesk.com/rest_api/docs/core/search")
public class SearchQuery {
@Option
@Documentation("Authentication information.")
private final BasicAuth dataStore;
@Option
@TextArea (3)
@Documentation("Search query.") (4)
private final String query;
@Option
@DefaultValue("relevance") (5)
@Documentation("One of updated_at, created_at, priority, status, or ticket_type. Defaults to sorting by relevance")
private final String sortBy;
@Option
@DefaultValue("desc")
@Documentation("One of asc or desc. Defaults to desc")
private final String sortOrder;
}| 1 | The configuration class is marked as a DataSet. Read more about configuration types. |
| 2 | @GridLayout defines the UI layout of this configuration. |
| 3 | A text area widget is bound to the Search query field. See all the available widgets. |
| 4 | The @Documentation annotation is used to document the component (configuration in this scope).
A Talend Component Kit Maven plugin can be used to generate the component documentation with all the configuration description and the default values. |
| 5 | A default value is defined for sorting the query result. |
Your component is configured. You can now create the component logic.
Defining the component mapper
| Mappers defined with this tutorial don’t implement the split part because HTTP calls are not split on many workers in this case. |
@Version
@Icon(value = Icon.IconType.CUSTOM, custom = "zendesk")
@PartitionMapper(name = "search")
@Documentation("Search component for zendesk query")
public class SearchMapper implements Serializable {
private final SearchQuery configuration; (1)
private final SearchClient searchClient; (2)
public SearchMapper(@Option("configuration") final SearchQuery configuration, final SearchClient searchClient) {
this.configuration = configuration;
this.searchClient = searchClient;
}
@PostConstruct
public void init() {
searchClient.base(configuration.getDataStore().getUrl()); (3)
}
@Assessor
public long estimateSize() {
return 1L;
}
@Split
public List<SearchMapper> split(@PartitionSize final long bundles) {
return Collections.singletonList(this); (4)
}
@Emitter
public SearchSource createWorker() {
return new SearchSource(configuration, searchClient); (5)
}
}| 1 | The component configuration that is injected by the component framework |
| 2 | The HTTP client created earlier in this tutorial. It is also injected by the framework via the mapper constructor. |
| 3 | The base URL of the HTTP client is defined using the configuration URL. |
| 4 | The mapper is returned in the split method because HTTP requests are not split. |
| 5 | A source is created to perform the HTTP request and return the search result. |
Defining the component source
Once the component logic implemented, you can create the source in charge of performing the HTTP request to the search API and converting the result to JsonObject records.
public class SearchSource implements Serializable {
private final SearchQuery config; (1)
private final SearchClient searchClient; (2)
private BufferizedProducerSupport<JsonValue> bufferedReader; (3)
private transient int page = 0;
private transient int previousPage = -1;
public SearchSource(final SearchQuery configuration, final SearchClient searchClient) {
this.config = configuration;
this.searchClient = searchClient;
}
@PostConstruct
public void init() { (4)
bufferedReader = new BufferizedProducerSupport<>(() -> {
JsonObject result = null;
if (previousPage == -1) {
result = search(config.getDataStore().getAuthorizationHeader(),
config.getQuery(), config.getSortBy(),
config.getSortBy() == null ? null : config.getSortOrder(), null);
} else if (previousPage != page) {
result = search(config.getDataStore().getAuthorizationHeader(),
config.getQuery(), config.getSortBy(),
config.getSortBy() == null ? null : config.getSortOrder(), page);
}
if (result == null) {
return null;
}
previousPage = page;
String nextPage = result.getString("next_page", null);
if (nextPage != null) {
page++;
}
return result.getJsonArray("results").iterator();
});
}
@Producer
public JsonObject next() { (5)
final JsonValue next = bufferedReader.next();
return next == null ? null : next.asJsonObject();
}
(6)
private JsonObject search(String auth, String query, String sortBy, String sortOrder, Integer page) {
final Response<JsonObject> response = searchClient.search(auth, query, sortBy, sortOrder, page);
if (response.status() == 200 && response.body().getInt("count") != 0) {
return response.body();
}
final String mediaType = extractMediaType(response.headers());
if (mediaType != null && mediaType.contains("application/json")) {
final JsonObject error = response.error(JsonObject.class);
throw new RuntimeException(error.getString("error") + "\n" + error.getString("description"));
}
throw new RuntimeException(response.error(String.class));
}
(7)
private String extractMediaType(final Map<String, List<String>> headers) {
final String contentType = headers == null || headers.isEmpty()
|| !headers.containsKey(HEADER_Content_Type) ? null :
headers.get(HEADER_Content_Type).iterator().next();
if (contentType == null || contentType.isEmpty()) {
return null;
}
// content-type contains charset and/or boundary
return ((contentType.contains(";")) ? contentType.split(";")[0] : contentType).toLowerCase(ROOT);
}
}| 1 | The component configuration injected from the component mapper. |
| 2 | The HTTP client injected from the component mapper. |
| 3 | A utility used to buffer search results and iterate on them one after another. |
| 4 | The record buffer is initialized with the init by providing the logic to iterate on the search result. The logic consists in getting the first result page and converting the result into JSON records. The buffer then retrieves the next result page, if needed, and so on. |
| 5 | The next method returns the next record from the buffer. When there is no record left, the buffer returns null. |
| 6 | In this method, the HTTP client is used to perform the HTTP request to the search API. Depending on the HTTP response status code, the results are retrieved or an error is thrown. |
| 7 | The extractMediaType method allows to extract the media type returned by the API. |
You now have created a simple Talend component that consumes a REST API.
To learn how to test this component, refer to this tutorial.
Testing a REST API
Testing code that consumes REST APIs can sometimes present many constraints: API rate limit, authentication token and password sharing, API availability, sandbox expiration, API costs, and so on.
As a developer, it becomes critical to avoid those constraints and to be able to easily mock the API response.
The component framework provides an API simulation tool that makes it easy to write unit tests.
This tutorial shows how to use this tool in unit tests. As a starting point, the tutorial uses the component that consumes Zendesk Search API and that was created in a previous tutorial. The goal is to add unit tests for it.
| For this tutorial, four tickets that have the open status have been added to the Zendesk test instance used in the tests. |
To learn more about the testing methodology used in this tutorial, refer to Component JUnit testing.
Creating the unit test
Create a unit test that performs a real HTTP request to the Zendesk Search API instance. You can learn how to create a simple unit test in this tutorial.
public class SearchTest {
@ClassRule
public static final SimpleComponentRule component = new SimpleComponentRule("component.package");
@Test
public void searchQuery() {
// Initiating the component test configuration (1)
BasicAuth basicAuth = new BasicAuth("https://instance.zendesk.com", "username", "password");
final SearchQuery searchQuery = new SearchQuery(basicAuth, "type:ticket status:open", "created_at", "desc");
// We convert our configuration instance to URI configuration (2)
final String uriConfig = SimpleFactory.configurationByExample()
.forInstance(searchQuery)
.configured().toQueryString();
// We create our job test pipeline (3)
Job.components()
.component("search", "zendesk://search?" + uriConfig)
.component("collector", "test://collector")
.connections()
.from("search").to("collector")
.build()
.run();
final List<JsonObject> res = component.getCollectedData(JsonObject.class);
assertEquals(4, res.size());
}
}| 1 | Initiating:
|
| 2 | Converting the configuration to a URI format that will be used in the job test pipeline,
using the SimpleFactory class provided by the component framework. Read more about job pipeline. |
| 3 | Creating the job test pipeline. The pipeline executes the search component and redirects the result to the test collector component, that collects the search result.
The pipeline is then executed.
Finally, the job result is retrieved to check that the four tickets have been received. You can also check that the tickets have the open status. |
The test is now complete and working. It performs a real HTTP request to the Zendesk instance.
Transforming the unit test into a mocked test
As an alternative, you can use mock results to avoid performing HTTP requests every time on the development environment. The real HTTP requests would, for example, only be performed on an integration environment.
To transform the unit test into a mocked test that uses a mocked response of the Zendesk Search API:
-
Add the two following JUnit rules provided by the component framework.
-
JUnit4HttpApi: This rule starts a simulation server that acts as a proxy and catches all the HTTP requests performed in the tests. This simulation server has two modes :-
capture : This mode forwards the captured HTTP request to the real server and captures the response.
-
simulation : this mode returns a mocked response from the responses already captured. This rule needs to be added as a class rule.
-
-
JUnit4HttpApi: This rule has a reference to the first rule. Its role is to configure the simulation server for every unit test. It passes the context of the running test to the simulation server. This rule needs to be added as a simple (method) rule.
-
Example to run in a simulation mode:
public class SearchTest {
@ClassRule
public static final SimpleComponentRule component = new SimpleComponentRule("component.package");
private final MavenDecrypter mavenDecrypter = new MavenDecrypter();
@ClassRule
public static final JUnit4HttpApi API = new JUnit4HttpApi() (1)
.activeSsl(); (2)
@Rule
public final JUnit4HttpApiPerMethodConfigurator configurator = new JUnit4HttpApiPerMethodConfigurator(API); (3)
@Test
public void searchQuery() {
// the exact same code as above
}| 1 | Creating and starting a simulation server for this test class. |
| 2 | Activating SSL on the simulation server by calling the activeSsl() method. This step is required because the consumed API uses SSL. |
| 3 | Adding the simulation server configuration provider that provides the test context to the simulation server. |
-
Make the test run in capture mode to catch the real API responses that can be used later in the simulated mode.
To do that, set a newtalend.junit.http.captureenvironment variable totrue. This tells the simulation server to run in a capture mode.
The captured response is saved in the resources/talend.testing.http package in a JSON format, then reused to perform the API simulation.
Testing a component
This tutorial focuses on writing unit tests for the input component that was created in this previous tutorial.
This tutorial covers:
-
How to load components in a unit test.
-
How to create a job pipeline.
-
How to run the test in standalone mode.
The test class is as follows:
public class HazelcastMapperTest {
@ClassRule
public static final SimpleComponentRule COMPONENTS = new SimpleComponentRule(HazelcastMapperTest.class
.getPackage().getName()); (1)
private static HazelcastInstance instance; (2)
@BeforeClass
public static void startInstanceWithData() { (3)
instance = Hazelcast.newHazelcastInstance();
final IMap<Object, Object> map = instance.getMap(HazelcastMapperTest.class.getSimpleName());
IntStream.range(0, 100).forEach(i -> map.put("test_" + i, "value #" + i));
}
@AfterClass
public static void stopInstance() { (4)
instance.getLifecycleService().shutdown();
}
@Test
public void run() { (5)
Job.components() (6)
.component("source", "Hazelcast://Input?configuration.mapName=" + HazelcastMapperTest.class.getSimpleName())
.component("output", "test://collector")
.connections()
.from("source").to("output")
.build()
.run();
final List<JsonObject> outputs = COMPONENTS.getCollectedData(JsonObject.class); (7)
assertEquals(100, outputs.size());
}
}| 1 | SimpleComponentRule is a JUnit rule that lets you load your component from a package. This rule also provides some test components like emitter and collector. Learn more about JUnit in this section. |
| 2 | Using an embedded Hazelcast instance to test the input component. |
| 3 | Creating an embedded Hazelcast instance and filling it with some test data. A map with the name of the test class is created and data is added to it. |
| 4 | Cleaning up the instance after the end of the tests. |
| 5 | Defining the unit test. It first creates a job pipeline that uses our input component. |
| 6 | The pipeline builder Job is used to create a job. It contains two components: the input component and the test collector component. The input component is connected to the collector component. Then the job is built and ran locally. |
| 7 | After the job has finished running. The COMPONENTS rule instance is used to get the collected data from the collector component.
Once this is done, it is possible to do some assertion on the collected data. |
Testing in a Continuous Integration environment
This tutorial shows how to adapt the test configuration of the Zendesk search component that was done in this previous tutorial to make it work in a Continuous Integration environment.
In the test, the Zendesk credentials are used directly in the code to perform a first capture of the API response. Then, fake credentials are used in the simulation mode because the real API is not called anymore.
However, in some cases, you can require to continue calling the real API on a CI server or on a specific environment.
To do that, you can adapt the test to get the credentials depending on the execution mode (simulation/passthrough).
Setting up credentials
These instructions concern the CI server or on any environment that requires real credentials.
This tutorial uses:
-
A Maven server that supports password encryption as a credential provider. Encryption is optional but recommended.
-
The
MavenDecrypterRuletest rule provided by the framework. This rule lets you get credentials from Maven settings using a server ID.
To create encrypted server credentials for the Zendesk instance:
-
Create a master password using the command:
mvn --encrypt-master-password <password>. -
Store this master password in the
settings-security.xmlfile of the~/.m2folder. -
Encrypt the Zendesk instance password using the command:
mvn --encrypt-password <zendesk-password>. -
Create a server entry under servers in Maven
settings.xmlfile located in the~/.m2folder.
<server>
<id>zendesk</id>
<username>username@email.com</username>
<password>The encrypted password {oL37x/xiSvwtlhrMQ=}</password>
</server>
You can store the settings-security.xml and settings.xml files elsewhere that the default location (~/.m2). To do that, set the path of the directory containing the files
in the talend.maven.decrypter.m2.location environment variable.
|
Adapting the unit test
-
Add the
MavenDecrypterRulerule to the test class. This rule allows to inject server information stored in Mavensettings.xmlfile to the test. The rule also decrypts credentials if they are encrypted.
public class SearchTest {
@Rule
public final MavenDecrypterRule mavenDecrypterRule = new MavenDecrypterRule(this);
}-
Inject the Zendesk server to the test. To do that, add a new field to the class with the
@DecryptedServerannotation, that holds the server ID to be injected.
public class SearchTest {
@Rule
public final MavenDecrypterRule mavenDecrypterRule = new MavenDecrypterRule(this);
@DecryptedServer("zendesk")
private Server server;
}The MavenDecrypterRule is able to inject the server instance into this class at runtime. The server instance contains the username and the decrypted password.
-
Use the
serverinstance in the test to get the real credentials in a secured manner.
BasicAuth basicAuth = new BasicAuth("https://instance.zendesk.com",
server.getUsername(),
server.getPassword());Once modified, the complete test class looks as follows:
public class SearchTest {
@ClassRule
public static final SimpleComponentRule component = new SimpleComponentRule("component.package");
private final MavenDecrypter mavenDecrypter = new MavenDecrypter();
@ClassRule
public static final JUnit4HttpApi API = new JUnit4HttpApi()
.activeSsl();
@Rule
public final JUnit4HttpApiPerMethodConfigurator configurator = new JUnit4HttpApiPerMethodConfigurator(API);
@Rule
public final MavenDecrypterRule mavenDecrypterRule = new MavenDecrypterRule(this);
@DecryptedServer("zendesk")
private Server server;
@Test
public void searchQuery() {
// Initiating the component test configuration
BasicAuth basicAuth = new BasicAuth("https://instance.zendesk.com", server.getUsername(), server.getPassword());
final SearchQuery searchQuery = new SearchQuery(basicAuth, "type:ticket status:open", "created_at", "desc");
// We convert our configuration instance to URI configuration
final String uriConfig = SimpleFactory.configurationByExample()
.forInstance(searchQuery)
.configured().toQueryString();
// We create our job test pipeline
Job.components()
.component("search", "zendesk://search?" + uriConfig)
.component("collector", "test://collector")
.connections()
.from("search").to("collector")
.build()
.run();
final List<JsonObject> res = component.getCollectedData(JsonObject.class);
assertEquals(4, res.size());
}
}This test will continue to work in simulation mode, because the API simulation proxy is activated.
Setting up the CI server in passthrough mode
This tutorial shows how to set up a CI server in passthrough mode using Jenkins.
-
Log in to Jenkins.
-
Click New Item to create a new build job.
-
Enter an Item name (Job name) and choose the freestyle job. Then click OK.
-
In the Source Code Management section, enter your project repository URL. A GitHub repository is used in this tutorial.
-
Specify the
masterbranch as Branches to build.
-
In the Build section, click Add build step and choose Invoke top-level Maven targets.
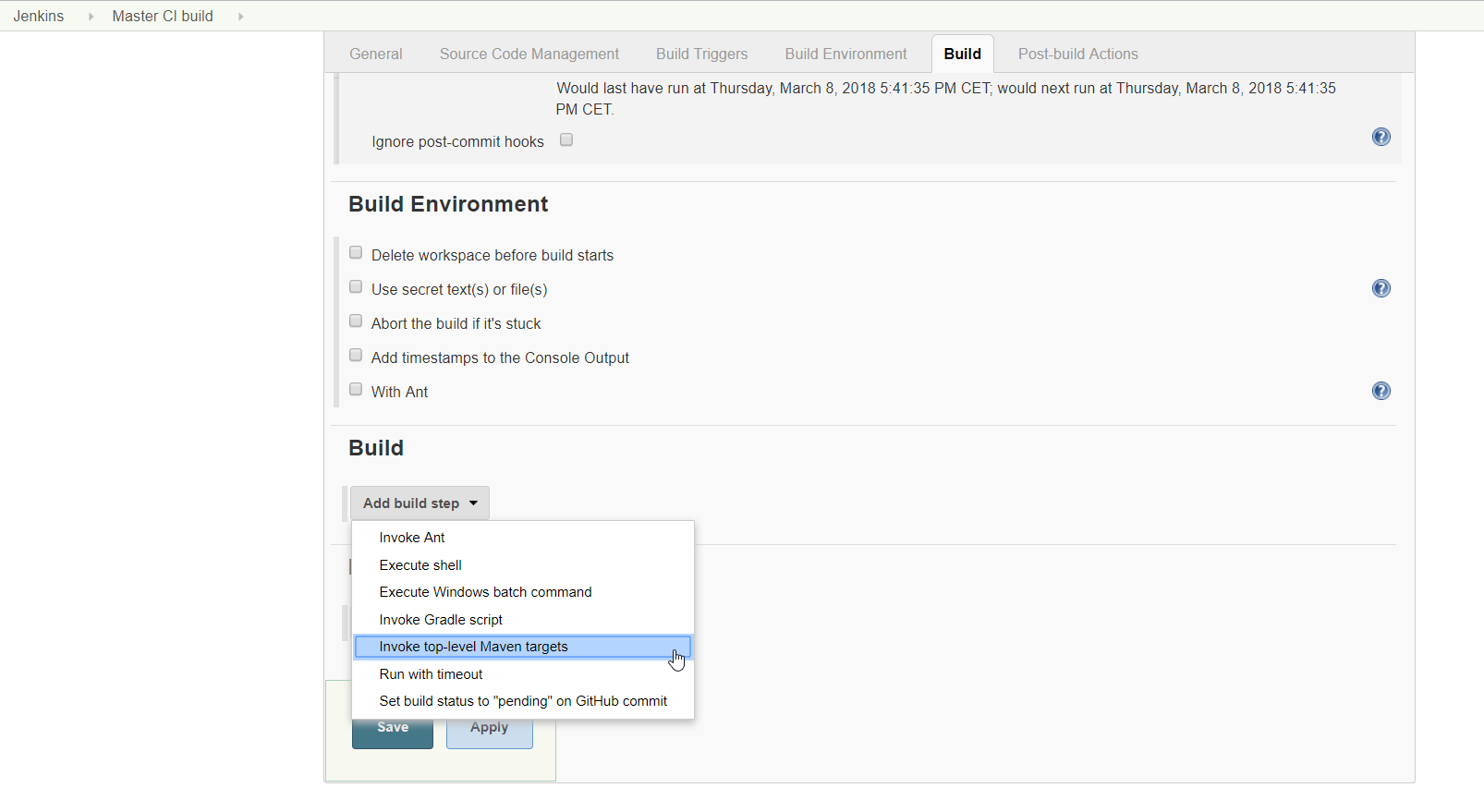
-
Choose your Maven version and enter the Maven build command. In this case:
clean install. Then, click Save.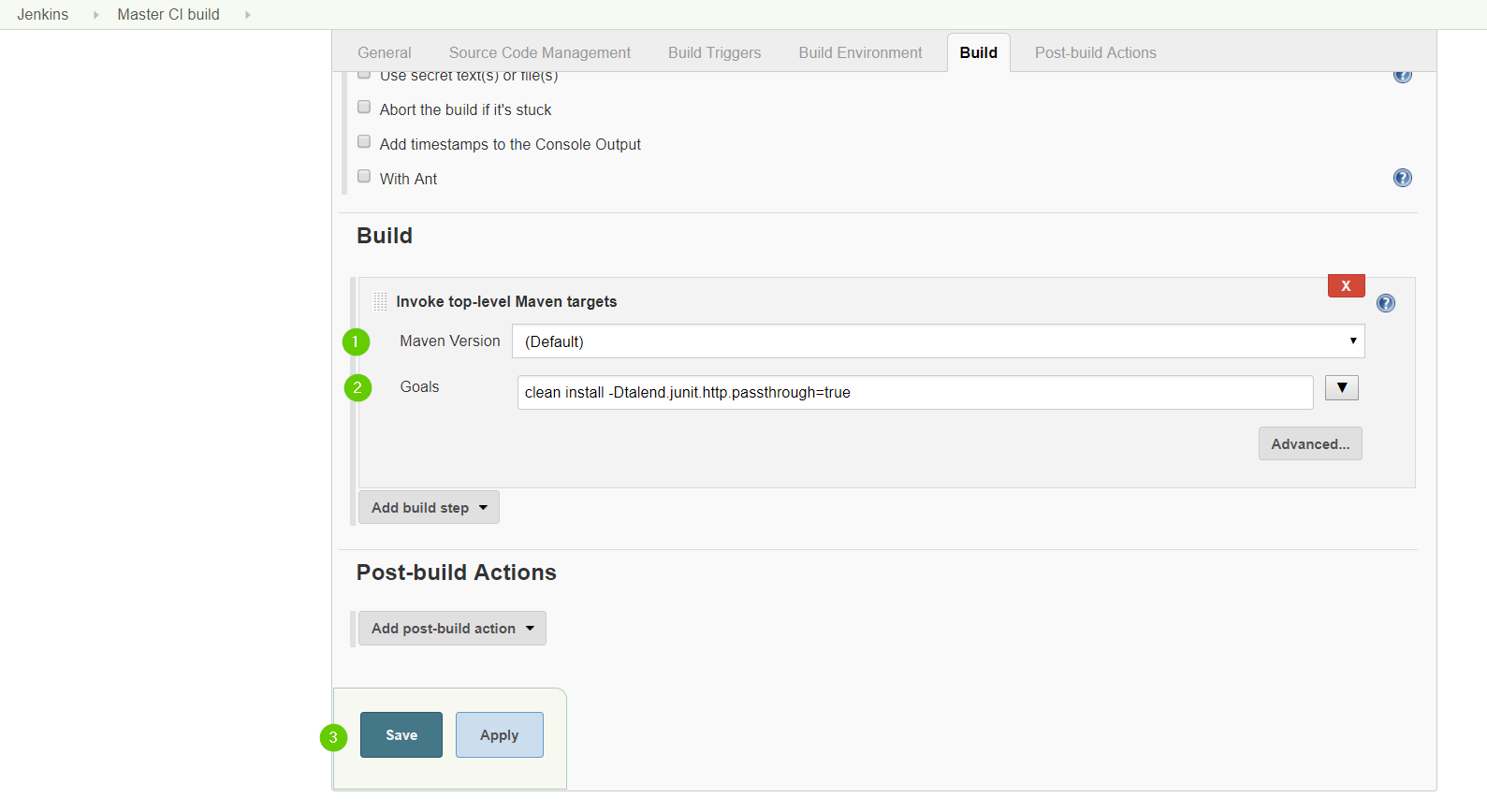
The
-Dtalend.junit.http.passthrough=trueoption is part of the build command. This option tells the API simulation proxy to run inpassthroughmode. This way, all the HTTP requests made in the test are forwarded to the real API server.The
MavenDecrypterRulerule allows to get the real credentials.You can configure the passthrough mode globally on your CI server by setting the talend.junit.http.passthroughenvironment variable totrue. -
Test the job by selecting Build now, and check that the job has built correctly.
Now your tests run in a simulation mode on your development environment and in a passthrough mode on your CI server.
Handling component version migration
Talend Component Kit provides a migration mechanism between two versions of a component to let you ensure backward compatibility.
For example, a new version of a component may have some new options that need to be remapped, set with a default value in the older versions, or disabled.
This tutorial shows how to create a migration handler for a component that needs to be upgraded from a version 1 to a version 2. The upgrade to the newer version includes adding new options to the component.
This tutorial assumes that you know the basics about component development and are familiar with component project generation and implementation.
Requirements
To follow this tutorial, you need:
-
Java 8
-
A Talend component development environment using Talend Component Kit. Refer to this document.
-
Have generated a project containing a simple processor component using the Talend Component Kit Starter.
Creating the version 1 of the component
First, create a simple processor component configured as follows:
-
Create a simple configuration class that represents a basic authentication and that can be used in any component requiring this kind of authentication.
@GridLayout({ @GridLayout.Row({ "username", "password" }) }) public class BasicAuth { @Option @Documentation("username to authenticate") private String username; @Option @Credential @Documentation("user password") private String password; }
-
Create a simple output component that uses the configuration defined earlier. The component configuration is injected into the component constructor.
@Version(1) @Icon(Icon.IconType.DEFAULT) @Processor(name = "MyOutput") @Documentation("A simple output component") public class MyOutput implements Serializable { private final BasicAuth configuration; public MyOutput(@Option("configuration") final BasicAuth configuration) { this.configuration = configuration; } @ElementListener public void onNext(@Input final JsonObject record) { } }The version of the configuration class corresponds to the component version.
By configuring these two classes, the first version of the component is ready to use a simple authentication mechanism.
Now, assuming that the component needs to support a new authentication mode following a new requirement, the next steps are:
-
Creating a version 2 of the component that supports the new authentication mode.
-
Handling migration from the first version to the new version.
Creating the version 2 of the component
The second version of the component needs to support a new authentication method and let the user choose the authentication mode he wants to use using a dropdown list.
-
Add an Oauth2 authentication mode to the component in addition to the basic mode. For example:
@GridLayout({ @GridLayout.Row({ "clientId", "clientSecret" }) }) public class Oauth2 { @Option @Documentation("client id to authenticate") private String clientId; @Option @Credential @Documentation("client secret token") private String clientSecret; }The options of the new authentication mode are now defined.
-
Wrap the configuration created above in a global configuration with the basic authentication mode and add an enumeration to let the user choose the mode to use. For example, create an
AuthenticationConfigurationclass as follows:@GridLayout({ @GridLayout.Row({ "authenticationMode" }), @GridLayout.Row({ "basic" }), @GridLayout.Row({ "oauth2" }) }) public class AuthenticationConfiguration { @Option @Documentation("the authentication mode") private AuthMode authenticationMode = AuthMode.Oauth2; // we set the default value to the new mode @Option @ActiveIf(target = "authenticationMode", value = {"Basic"}) @Documentation("basic authentication") private BasicAuth basic; @Option @ActiveIf(target = "authenticationMode", value = {"Oauth2"}) @Documentation("oauth2 authentication") private Oauth2 oauth2; /** * This enum holds the authentication mode supported by this configuration */ public enum AuthMode { Basic, Oauth2; } }Using the @ActiveIfannotation allows to activate the authentication type according to the selected authentication mode.
-
Edit the component to use the new configuration that supports an additional authentication mode. Also upgrade the component version from 1 to 2 as its configuration has changed.
@Version(2) // upgrade the component version @Icon(Icon.IconType.DEFAULT) @Processor(name = "MyOutput") @Documentation("A simple output component") public class MyOutput implements Serializable { private final AuthenticationConfiguration configuration; // use the new configuration public MyOutput(@Option("configuration") final AuthenticationConfiguration configuration) { this.configuration = configuration; } @ElementListener public void onNext(@Input final JsonObject record) { } }
The component now supports two authentication modes in its version 2. Once the new version is ready, you can implement the migration handler that will take care of adapting the old configuration to the new one.
Handling the migration from the version 1 to the version 2
What can happen if an old configuration is passed to the new component version?
It simply fails, as the version 2 does not recognize the old version anymore.
For that reason, a migration handler that adapts the old configuration to the new one is required.
It can be achieved by defining a migration handler class in the @Version annotation of the component class.
| An old configuration may already be persisted by an application that integrates the version 1 of the component (Studio or web application). |
Declaring the migration handler
-
Add a migration handler class to the component version.
@Version(value = 2, migrationHandler = MyOutputMigrationHandler.class)
-
Create the migration handler class
MyOutputMigrationHandler.public class MyOutputMigrationHandler implements MigrationHandler{ (1) @Override public Map<String, String> migrate(final int incomingVersion, final Map<String, String> incomingData) { (2) // Here we will implement our migration logic to adapt the version 1 of the component to the version 2 return incomingData; } }1 The migration handler class needs to implement the MigrationHandlerinterface.2 The MigrationHandlerinterface specifies themigratemethod. This method references:
-
the incoming version, which is the version of the configuration that we are migrating from
-
a map (key, value) of the configuration, where the key is the configuration path and the value is the value of the configuration.
-
Implementing the migration handler
| You need to be familiar with the component configuration path construction to better understand this part. Refer to Defining component layout and configuration. |
As a reminder, the following changes were made since the version 1 of the component:
-
The configuration
BasicAuthfrom the version 1 is not the root configuration anymore, as it is underAuthenticationConfiguration. -
AuthenticationConfigurationis the new root configuration. -
The component supports a new authentication mode (Oauth2) which is the default mode in the version 2 of the component.
To migrate the old component version to the new version and to keep backward compatibility, you need to:
-
Remap the old configuration to the new one.
-
Give the adequate default values to some options.
In the case of this scenario, it means making all configurations based on the version 1 of the component have the authenticationMode set to basic by default and remapping the old basic authentication configuration to the new one.
public class MyOutputMigrationHandler implements MigrationHandler{
@Override
public Map<String, String> migrate(final int incomingVersion, final Map<String, String> incomingData) {
if(incomingVersion == 1){ (1)
// remapping the old configuration (2)
String userName = incomingData.get("configuration.username");
String password = incomingData.get("configuration.password");
incomingData.put("configuration.basic.username", userName);
incomingData.put("configuration.basic.password", password);
// setting default value for authenticationMode to Basic (3)
incomingData.put("configuration.authenticationMode", "Basic");
}
return incomingData; (4)
}
}| 1 | Safety check of the incoming data version to make sure to only apply the migration logic to the version 1. |
| 2 | Mapping the old configuration to the new version structure. As the BasicAuth is now under the root configuration class, its path changes and becomes configuration.basic.*. |
| 3 | Setting a new default value to the authenticationMode as it needs to be set to Basic for configuration coming from version 1. |
| 4 | Returning the new configuration data. |
| if a configuration has been renamed between 2 component versions, you can get the old configuration option from the configuration map by using its old path and set its value using its new path. |
You can now upgrade your component without losing backward compatibility.