Talend Component framework relies on several primitive components.
They can all use @PostConstruct and @PreDestroy to initialize/release
some underlying resource at the beginning/end of the processing.
in distributed environments class' constructor will be called on cluster manager node, methods annotated with
@PostConstruct and @PreDestroy annotations will be called on worker nodes. Thus, partition plan computation and pipeline task
will be performed on different nodes.
|
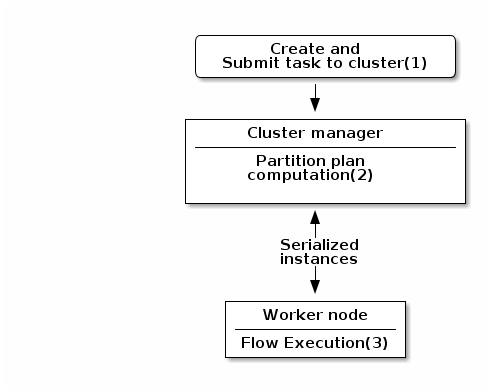
-
Created task consists of Jar file, containing class, which describes pipeline(flow) which should be processed in cluster.
-
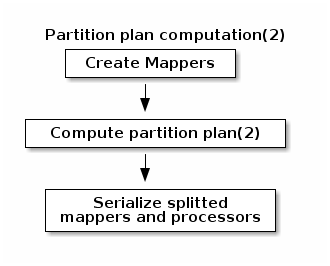
During partition plan computation step pipeline is analyzed and split into stages. Cluster Manager node instantiates mappers/processors gets estimated data size using mappers, splits created mappers according to the estimated data size. All instances are serialized and sent to Worker nodes afterwards.
-
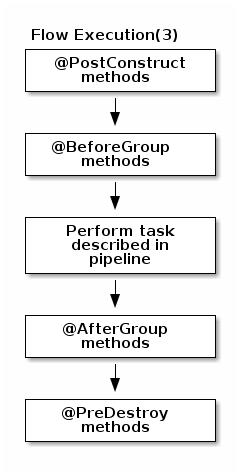
Serialized instances are received and deserialized, methods annotated with @PostConstruct annotation are called. After that, pipeline execution is started. Processor’s @BeforeGroup annotated method is called before processing first element in chunk. After processing number of records estimated as chunk size, Processor’s @AfterGroup annotated method called. Chunk size is calculated depending on environment the pipeline is processed by. After pipeline is processed, methods annotated with @PreDestroy annotation are called.
all framework managed methods MUST be public too. Private methods are ignored.
|
| in term of design the framework tries to be as declarative as possible but also to stay extensible not using fixed interfaces or method signatures. This will allow to add incrementally new features of the underlying implementations. |
PartitionMapper
A
PartitionMapperis a component able to split itself to make the execution more efficient.
This concept is borrowed to big data world and useful only in this context (BEAM executions).
Overall idea is to divide the work before executing it to try to reduce the overall execution time.
The process is the following:
-
Estimate the size of the data you will work on. This part is often heuristic and not very precise.
-
From that size the execution engine (runner for beam) will request the mapper to split itself in N mappers with a subset of the overall work.
-
The leaf (final) mappers will be used as a
Producer(actual reader) factory.
this kind of component MUST be Serializable to be distributable.
|
Definition
A partition mapper requires 3 methods marked with specific annotations:
-
@Assessorfor the evaluating method -
@Splitfor the dividing method -
@Emitterfor theProducerfactory
@Assessor
The assessor method will return the estimated size of the data related to the component (depending its configuration).
It MUST return a Number and MUST not take any parameter.
Here is an example:
@Assessor
public long estimateDataSetByteSize() {
return ....;
}@Split
The split method will return a collection of partition mappers and can take optionally a @PartitionSize long
value which is the requested size of the dataset per sub partition mapper.
Here is an example:
@Split
public List<MyMapper> split(@PartitionSize final long desiredSize) {
return ....;
}Producer
A
Produceris the component interacting with a physical source. It produces input data for the processing flow.
A producer is a very simple component which MUST have a @Producer method without any parameter and returning any data:
@Producer
public MyData produces() {
return ...;
}Processor
A
Processoris a component responsible to convert an incoming data to another model.
A processor MUST have a method decorated with @ElementListener taking an incoming data and returning the processed data:
@ElementListener
public MyNewData map(final MyData data) {
return ...;
}
this kind of component MUST be Serializable since it is distributed.
|
if you don’t care much of the type of the parameter and need to access data on a "map like" based rule set, then you can
use JsonObject as parameter type and Talend Component will just wrap the data to enable you to access it as a map. The parameter
type is not enforced, i.e. if you know you will get a SuperCustomDto then you can use that as parameter type but for generic
component reusable in any chain it is more than highly encouraged to use JsonObject until you have your an evaluation language
based processor (which has its own way to access component). Here is an example:
|
@ElementListener
public MyNewData map(final JsonObject incomingData) {
String name = incomingData.getString("name");
int name = incomingData.getInt("age");
return ...;
}
// equivalent to (using POJO subclassing)
public class Person {
private String age;
private int age;
// getters/setters
}
@ElementListener
public MyNewData map(final Person person) {
String name = person.getName();
int name = person.getAge();
return ...;
}A processor also supports @BeforeGroup and @AfterGroup which MUST be methods without parameters and returning void (result would be ignored).
This is used by the runtime to mark a chunk of the data in a way which is estimated good for the execution flow size.
| this is estimated so you don’t have any guarantee on the size of a group. You can literally have groups of size 1. |
The common usage is to batch records for performance reasons:
@BeforeGroup
public void initBatch() {
// ...
}
@AfterGroup
public void endBatch() {
// ...
}
it is a good practise to support a maxBatchSize here and potentially commit before the end of the group in case
of a computed size which is way too big for your backend.
|
Multiple outputs
In some case you may want to split the output of a processor in two. A common example is "main" and "reject" branches where part of the incoming data are put in a specific bucket to be processed later.
This can be done using @Output. This can be used as a replacement of the returned value:
@ElementListener
public void map(final MyData data, @Output final OutputEmitter<MyNewData> output) {
output.emit(createNewData(data));
}Or you can pass it a string which will represent the new branch:
@ElementListener
public void map(final MyData data,
@Output final OutputEmitter<MyNewData> main,
@Output("rejected") final OutputEmitter<MyNewDataWithError> rejected) {
if (isRejected(data)) {
rejected.emit(createNewData(data));
} else {
main.emit(createNewData(data));
}
}
// or simply
@ElementListener
public MyNewData map(final MyData data,
@Output("rejected") final OutputEmitter<MyNewDataWithError> rejected) {
if (isSuspicious(data)) {
rejected.emit(createNewData(data));
return createNewData(data); // in this case we continue the processing anyway but notified another channel
}
return createNewData(data);
}Multiple inputs
Having multiple inputs is closeto the output case excep it doesn’t require a wrapper OutputEmitter:
@ElementListener
public MyNewData map(@Input final MyData data, @Input("input2") final MyData2 data2) {
return createNewData(data1, data2);
}@Input takes the input name as parameter, if not set it uses the main (default) input branch.
| due to the work required to not use the default branch it is recommended to use it when possible and not name its branches depending on the component semantic. |
Output
An
Outputis aProcessorreturning no data.
Conceptually an output is a listener of data. It perfectly matches the concept of processor. Being the last of the execution chain or returning no data will make your processor an output:
@ElementListener
public void store(final MyData data) {
// ...
}