Each type of component has its own execution logic. The same basic logic is applied to all components of the same type, and is then extended to implement each component specificities. The project generated from the starter already contains the basic logic for each component.
Talend Component Kit framework relies on several primitive components.
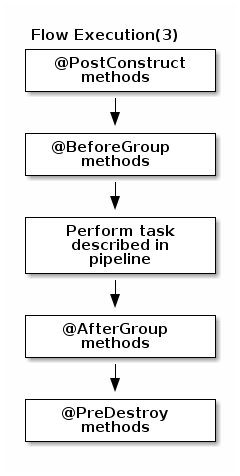
All components can use @PostConstruct and @PreDestroy annotations to initialize or release some underlying resource at the beginning and the end of a processing.
In distributed environments, class constructor are called on cluster manager nodes. Methods annotated with @PostConstruct and @PreDestroy are called on worker nodes. Thus, partition plan computation and pipeline tasks are performed on different nodes.
|
-
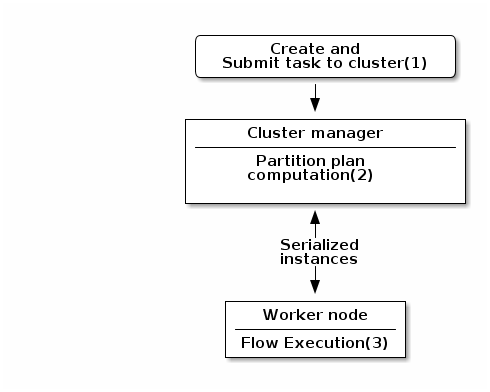
The created task is a JAR file containing class information, which describes the pipeline (flow) that should be processed in cluster.
-
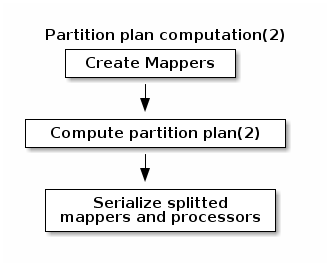
During the partition plan computation step, the pipeline is analyzed and split into stages. The cluster manager node instantiates mappers/processors, gets estimated data size using mappers, and splits created mappers according to the estimated data size.
All instances are then serialized and sent to the worker node. -
Serialized instances are received and deserialized. Methods annotated with
@PostConstructare called. After that, pipeline execution starts. The@BeforeGroupannotated method of the processor is called before processing the first element in chunk.
After processing the number of records estimated as chunk size, the@AfterGroupannotated method of the processor is called. Chunk size is calculated depending on the environment the pipeline is processed by. Once the pipeline is processed, methods annotated with@PreDestroyare called.
| All the methods managed by the framework must be public. Private methods are ignored. |
| The framework is designed to be as declarative as possible but also to stay extensible by not using fixed interfaces or method signatures. This allows to incrementally add new features of the underlying implementations. |