In this tutorial, we will walk through the creation of a complete Talend input component from scratch for hazelcast using Talend Component Framework that we will reference in this tutorial as TCK.
We will create an input component for hazelcast. Hazelcast will be a prefect example to show how to create an input component for distributed systems. Hazelcast is an in-memory distributed data grid. You can read more about it here hazelcast.org/ but all what you will need to know to follow this tutorial is that hazelcast is a distributed system that can store data.
So, Let’s start by creating the component project.
Project creation
TCK project is a simple java project with some specific configuration and dependencies. You can choose your preferred build tool from Maven or Gradle as TCK supports both of them. But, in this tutorial, we will use maven.
Let’s generate the project structure using Talend Starter TOOLKIT .
For that, please go to starter-toolkit.talend.io/ and fill in the project information as shown in the screen capture bellow, then click finish and click download as a zip
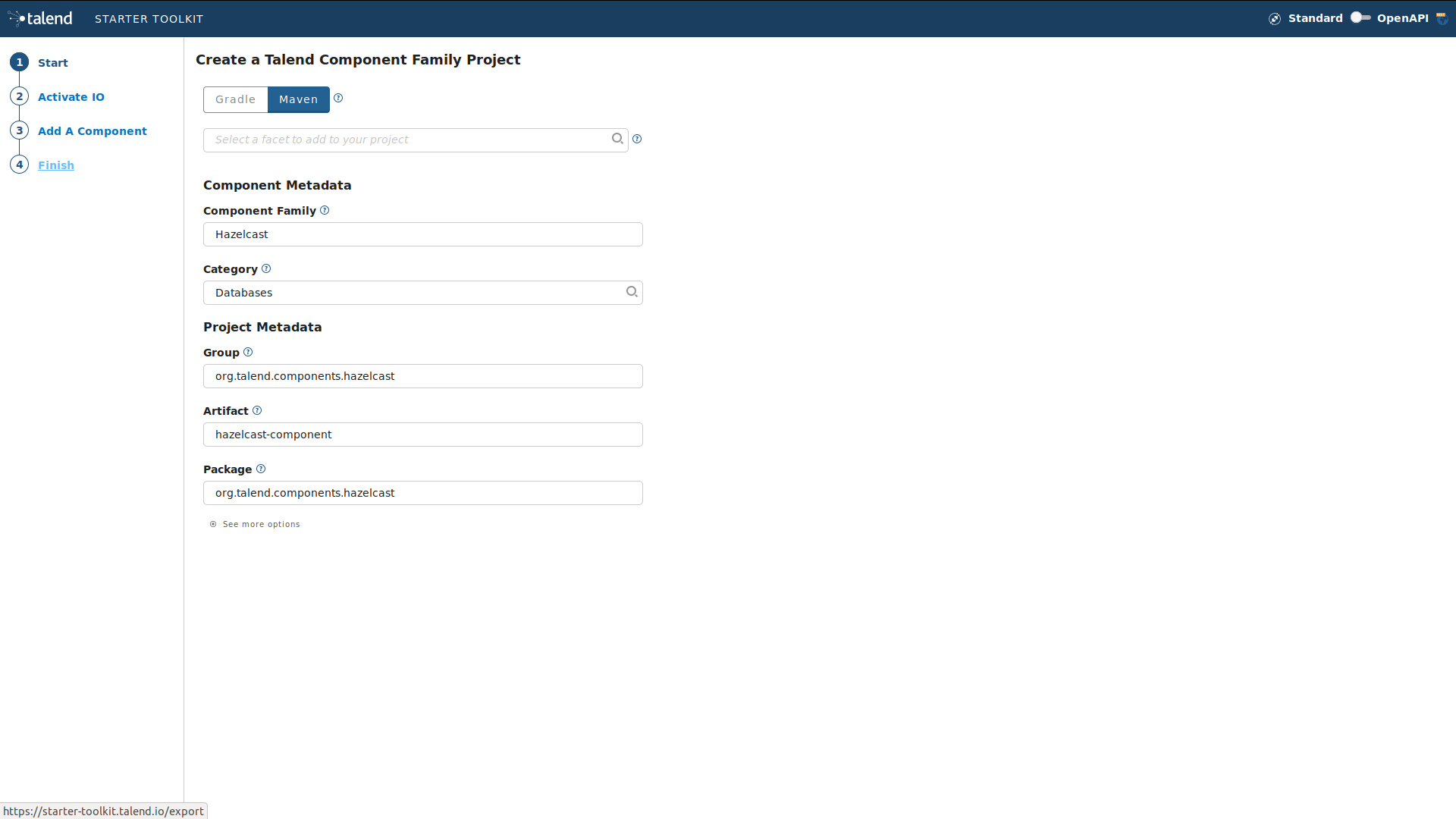
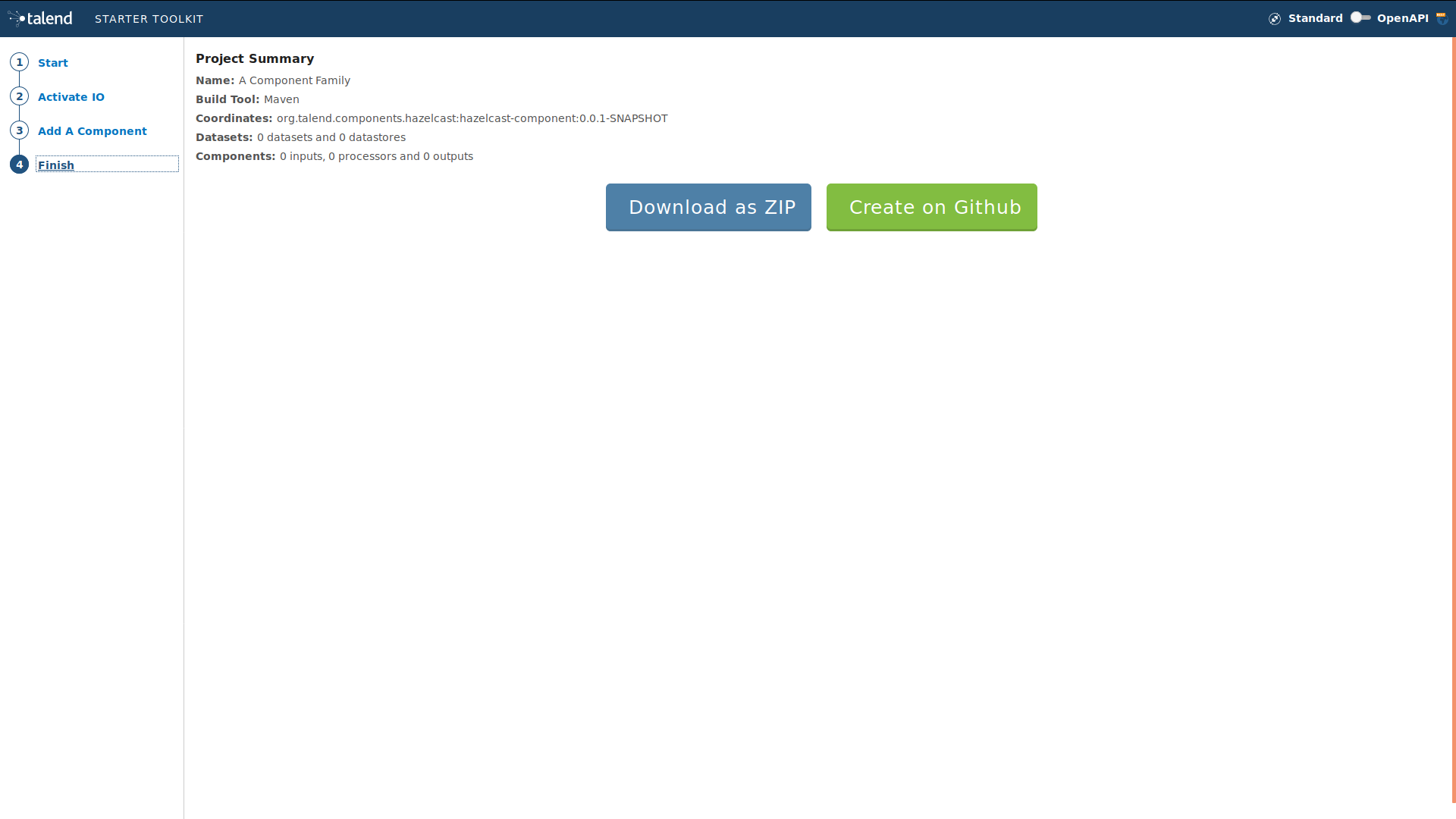
Extract the zip file into your workspace and import it to your preferred IDE. We will use Intellij IDE, but you can use Eclipse or any other IDE that you are comfortable with.
| You can use the starter toolkit to design the full configuration of the component, but in this tutorial we will do that manually to explain some concepts of TCK. |
Let’s explore the generated pom.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.talend.components.hazelcast</groupId>
<artifactId>hazelcast-component</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Component Hazelcast</name>
<description>A generated component project</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--
Set it to true if you want the documentation to be rendered as HTML and PDF
You can also use it on the command line: -Dtalend.documentation.htmlAndPdf=true
-->
<talend.documentation.htmlAndPdf>false</talend.documentation.htmlAndPdf>
<!--
if you want to deploy into the studio you can use the related goal:
mvn package talend-component:deploy-in-studio -Dtalend.component.studioHome=/path/to/studio
TIP: it is recommended to set this property into your settings.xml in an active by default profile.
-->
<talend.component.studioHome />
</properties>
<dependencies>
<dependency>
<groupId>org.talend.sdk.component</groupId>
<artifactId>component-api</artifactId>
<version>1.1.12</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.talend.sdk.component</groupId>
<artifactId>talend-component-maven-plugin</artifactId>
<version>1.1.12</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
<compilerId>javac</compilerId>
<fork>true</fork>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.0.0-M3</version>
<configuration>
<trimStackTrace>false</trimStackTrace>
<runOrder>alphabetical</runOrder>
</configuration>
</plugin>
</plugins>
</build>
</project>Change the name tag to a more relevant one, for example <name>Component Hazelcast</name>
-
component-apidependency provides us with the necessary API to develop the components. -
talend-component-maven-pluginprovides building and validation tools for the components development.
Also the java compiler needs some Talend specific configuration for the components to work correctly. The most important is the option -parameters that preserve the parameters name needed for some introspection feature that TCK rely on.
Let’s download the mvn dependencies declared in the pom.xml file.
$ mvn clean compileYou should get a BUILD SUCCESS at this point as shown bellow.
[INFO] Scanning for projects...
[INFO]
[INFO] -----< org.talend.components.hazelcast:talend-component-hazelcast >-----
[INFO] Building Component :: Hazelcast 1.0.0-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1.311 s
[INFO] Finished at: 2019-09-03T11:42:41+02:00
[INFO] ------------------------------------------------------------------------Now, let’s create the project structure. For that, create the following folder structure as the following:
$ mkdir -p src/main/java
$ mkdir -p src/main/resourcesAnd then, let’s create the component java packages.
| The Package are mandatory in the component model and you can’t use the default one (no package). It’s recommended to create unique package by component to be able to reuse them as dependencies in other component for example or to guarantee an isolation while writing unit tests. |
$ mkdir -p src/main/java/org/talend/components/hazelcast
$ mkdir -p src/main/resources/org/talend/components/hazelcastNow, the project is correctly setup, let’s continue by registering the component family and setting up some i18n properties
Registering the Hazelcast components family
Every family (group) of components needs to be registered to be loaded by components server and then to be available in Talend Studio components palette for example.
The family registration is done via the package-info.java file so let’s create it.
For that move to src/main/java/org/talend/components/hazelcast package and create a package-info.java file as bellow.
@Components(family = "Hazelcast", categories = "Databases")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Components;
import org.talend.sdk.component.api.component.Icon;@Components: declare the family name and the categories to which it will belongs @Icon: declare the component family icon. this is mostly used in the studio metadata tree.
TCK also provides i18n support via java properties files to customize and translate the display name of some properties like the family name or, as we will see later in this tutorial, the component configuration labels.
So, let’s create the i18n file in the resources folder.
For that, please move to src/main/resources/org/talend/components/hazelcast and create a Messages.properties file as bellow:
# An i18n name for the component family
Hazelcast._displayName=HazelcastFor the family icon, defined in the package-info.java file, an icon image needs to be provided in the resources/icons
folder.
TCK support svg and png format for the icons.
So let’s create the icons folder and put an icon image for our hazelcast family.
$ mkdir -p /src/main/resources/iconsI will use the hazelcast icon from there official github repository that you can get from here avatars3.githubusercontent.com/u/1453152?s=200&v=4
Download the image and rename it to Hazelcast_icon32.png.
The name template is important and it should match <Icon id from the package-info>_icon.32.png
That’s all for the component registration. Now we can start designing the component configuration
Hazelcast component configuration
All the I/O components follow a predefined model of configuration. The configuration needs to be composed of two parts:
-
Datastore: define all the properties that will let the component connect to the targeted system.
-
Dataset: define the data that will be read or written from/to the targeted system.
Datastore
To connect to hazelcast cluster we will need the cluster ip address, the group name and the password of the targeted cluster.
In the component this will be represented by a simple POJO.
So, let’s create a class file HazelcastDatastore.java in serc/main/java/org/talend/components/hazelcast
folder.
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.configuration.constraint.Required;
import org.talend.sdk.component.api.configuration.type.DataStore;
import org.talend.sdk.component.api.configuration.ui.layout.GridLayout;
import org.talend.sdk.component.api.configuration.ui.widget.Credential;
import org.talend.sdk.component.api.meta.Documentation;
import java.io.Serializable;
@GridLayout({
@GridLayout.Row("clusterIpAddress"),
@GridLayout.Row({"groupName", "password"})
})
@DataStore("HazelcastDatastore")
@Documentation("Hazelcast Datastore configuration")
public class HazelcastDatastore implements Serializable {
@Option
@Required
@Documentation("The hazelcast cluster ip address")
private String clusterIpAddress;
@Option
@Documentation("cluster group name")
private String groupName;
@Option
@Credential
@Documentation("cluster password")
private String password;
// Getters & Setters omitted for simplicity
// You need to generate them
}Let’s walk through the annotations used here :
-
@GridLayout: define the ui layout of this configuration in a grid manner. -
@DataStore: mark this POJO as being a data store with the idHazelcastDatastorethat can be used to reference the datastore in the i18n files or some services -
@Documentation: document classes and properties. then TCK rely on those metadata to generate a documentation for the component. -
@Option: mark class’s attributes as being a configuration entry. -
@Credential: mark an Option as being a sensible data that need to be encrypted before it’s stored. -
@Required: mark a configuration as being required.
Now let’s define the i18n properties of the data store.
In the Messages.properties file let add the following lines:
#datastore
Hazelcast.datastore.HazelcastDatastore._displayName=Hazelcast Connection
HazelcastDatastore.clusterIpAddress._displayName=Cluster ip address
HazelcastDatastore.groupName._displayName=Group Name
HazelcastDatastore.password._displayName=PassowrdBy this, we have defined the hazelcast datastore. Let’s see now for the dataset
Dataset
In hazelcast there is different types of data store that can be found. You can manipulate Maps, List, Set, Cache, Locks, Queue, Topic….
In this tutorial we will focus on Maps as an example, but all what we will see is also applicable to all the other data structures.
To read/write from a map we will need the map name.
So, let’s create the dataset classe.
For that create HazelcastDataset.java
file in src/main/java/org/talend/components/hazelcast
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.configuration.type.DataSet;
import org.talend.sdk.component.api.configuration.ui.layout.GridLayout;
import org.talend.sdk.component.api.meta.Documentation;
import java.io.Serializable;
@GridLayout({
@GridLayout.Row("connection"),
@GridLayout.Row("mapName")
})
@DataSet("HazelcastDataset")
@Documentation("Hazelcast dataset")
public class HazelcastDataset implements Serializable {
@Option
@Documentation("Hazelcast connection")
private HazelcastDatastore connection;
@Option
@Documentation("Hazelcast map name")
private String mapName;
// Getters & Setters omitted for simplicity
// You need to generate them
}Here, we have a new annotation @Dataset that mark this classe as being a dataset.
Note that we also have a reference to the datastore. this is a part of the components model.
Now and as we have done with the datastore, let’s define the i18n properties of the dataset.
for that add the following lines to the Messages.properties file
#dataset
Hazelcast.dataset.HazelcastDataset._displayName=Hazelcast Map
HazelcastDataset.connection._displayName=Connection
HazelcastDataset.mapName._displayName=Map NameThat’s all we need for the component configuration. Now let’s create the Source that will read the data from the hazelcast map.
Source
Source is the class responsible of reading the data from the configured dataset.
A source get the configuration instance that will be injected by TCK at runtime and will use it to connect to the targeted system to read the data.
Here is a simple source for Hazelcast.
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.record.Record;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.IOException;
import java.io.Serializable;
@Version
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Emitter(name = "Input")
@Documentation("Hazelcast source")
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
public HazelcastSource(@Option("configuration") final HazelcastDataset configuration) {
this.dataset = configuration;
}
@PostConstruct
public void init() throws IOException {
//Here we can init connections
}
@Producer
public Record next() {
// provide a record every time it called. return null if there is no more data
return null;
}
@PreDestroy
public void release() {
// clean and release any resources
}
}Note that this class is annotated with @Emitter which mark this class as being a source that will produce records. We find
the Icon annotation that define the icon of the component. Here we will use the same icon as the family one but you can use
different icon if you want.
The constructor of the source class let TCK inject the required configuration to the source. We can also inject some common services provided by TCK or other services that we can define in the component. We will see the service part later in this tutorial.
The method annotated with @PostConstruct is used to prepare resource or open a connection for example.
The method annotated with @Producer is responsible of retuning the next record if any. the method will return null if no
more record can be read.
The method annotated with @PreDestroy is responsible of cleaning any resource that was used or opened in the Source.
As for the configuration. the source also need some i18n properties to provide human readable display name of the source.
For that, please add the following line to the Messages.properties file.
#Source
Hazelcast.Input._displayName=InputAt this point we can already see the result in the Talend component web tester to see how the configuration looks like and validate our layout visually.
For that, let’s execute this command in the project folder.
$ mvn clean install talend-component:webThis will start the component web tester and deploy the component to it. Then you can browse it at localhost:8080/
[INFO]
[INFO] --- talend-component-maven-plugin:1.1.12:web (default-cli) @ talend-component-hazelcast ---
[16:46:52.361][INFO ][.WebServer_8080][oyote.http11.Http11NioProtocol] Initializing ProtocolHandler ["http-nio-8080"]
[16:46:52.372][INFO ][.WebServer_8080][.catalina.core.StandardService] Starting service [Tomcat]
[16:46:52.372][INFO ][.WebServer_8080][e.catalina.core.StandardEngine] Starting Servlet engine: [Apache Tomcat/9.0.22]
[16:46:52.378][INFO ][.WebServer_8080][oyote.http11.Http11NioProtocol] Starting ProtocolHandler ["http-nio-8080"]
[16:46:52.390][INFO ][.WebServer_8080][g.apache.meecrowave.Meecrowave] --------------- http://localhost:8080
...
[INFO]
You can now access the UI at http://localhost:8080
[INFO] Enter 'exit' to quit
[INFO] Initializing class org.talend.sdk.component.server.front.ComponentResourceImpl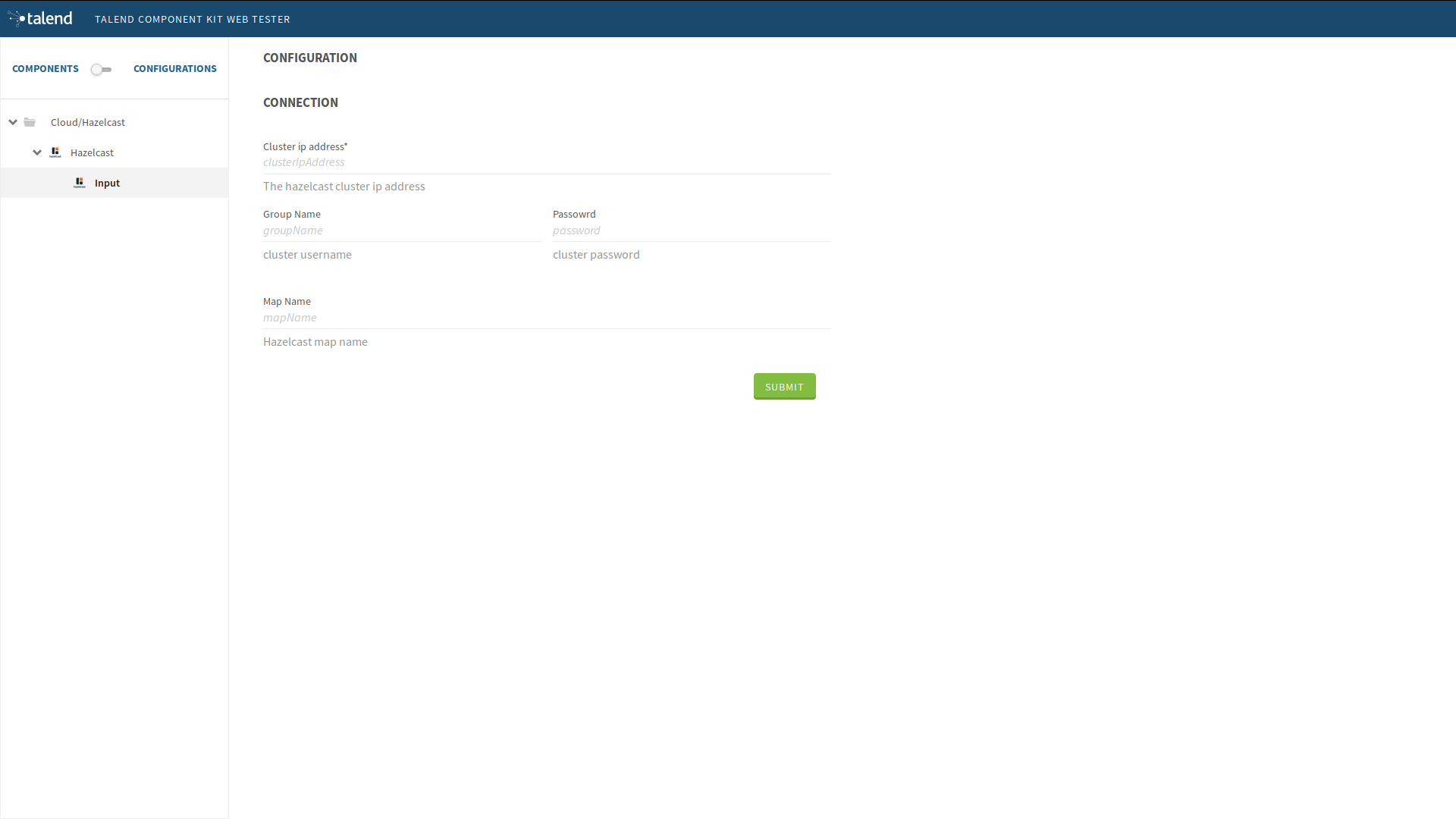
Now that we have setup our source let start creating some hazelcast specific code to connect to a cluster and read some values for a map.
Source implementation for Hazelcast
To work with hazelcast we will need to add the hazelcast-client maven dependency to the pom.xml of the project.
Add this dependency into the dependencies tag in the pom.xml
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-client</artifactId>
<version>3.12.2</version>
</dependency>Let’s get an hazelcast instance in the @PostConstruct method. for that, let’s start by declaring a HazelcastInstance
attribute in the source class. Note that any non serializable attribute needs to be marked as transient to avoid serialization
issues. Then let’s implement the post construct method.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.record.Record;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import static java.util.Collections.singletonList;
@Version
@Emitter(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
public HazelcastSource(@Option("configuration") final HazelcastDataset configuration) {
this.dataset = configuration;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Producer
public Record next() {
// provide a record every time it called. return null if there is no more data
return null;
}
@PreDestroy
public void release() {
// clean and release any resources
}
}Here, we have mapped the component configuration to hazelcast client configuration to create a hazelcast instance that we will use later to get the map by it’s name and then read the data from it. The code is straight forward as you can notice. To keep it simple, we did expose only the required configuration in the component.
Now let’s implement the code that will be responsible of reading the data from the hazelcast map.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.Iterator;
import java.util.Map;
import static java.util.Collections.singletonList;
@Version
@Emitter(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private transient Iterator<Map.Entry<String, String>> mapIterator;
private final RecordBuilderFactory recordBuilderFactory;
public HazelcastSource(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Producer
public Record next() {
// provide a record every time it called. return null if there is no more data
if (mapIterator == null) {
// Get the Distributed Map from Cluster.
IMap<String, String> map = hazelcastInstance.getMap(dataset.getMapName());
mapIterator = map.entrySet().iterator();
}
if (!mapIterator.hasNext()) {
return null;
}
final Map.Entry<String, String> entry = mapIterator.next();
return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build();
}
@PreDestroy
public void release() {
// clean and release any resources
}
}Let’s walk thought the implementation of the Producer annotated method.
We start by checking if the map iterator was already initialized and if not we get the map by it’s name and we initialize it.
we do that in the @Producer method to ensure the map is only initialized if the next() method is called (a lazy initialisation). we also avoid the
map initialization in the PostConstruct as the hazelcast map is not serializable.
Note that all the objects initialized in the PostConstruct method needs to be serializable as the source
may be serialized and sent to an other worker in a distributed cluster for it’s execution.
|
From the map, we create an iterator on the map keys that we will use to read from the map. then we will transform every pair of key/value to a Talend Record with a key, value Object on every call to next.
Notice here that we have used the RecordBuilderFactory class which is a built in service in TCK that we have injected via
the Source constructor. This service is a factory to create Talend Records.
Now the next() method will produce a Record every time it’s called. the method will return null if no more data is in the map.
That’s all for the
@Producerannotated method.Now let’s implement the
@PreDestroyannotated method which will be responsible of releasing all the resource used by the Source. So here we will need to shutdown the hazelcast client instance to release any connection between the component and hazelcast cluster.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.Iterator;
import java.util.Map;
import static java.util.Collections.singletonList;
@Version
@Emitter(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private transient Iterator<Map.Entry<String, String>> mapIterator;
private final RecordBuilderFactory recordBuilderFactory;
public HazelcastSource(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Producer
public Record next() {
// provide a record every time it called. return null if there is no more data
if (mapIterator == null) {
// Get the Distributed Map from Cluster.
IMap<String, String> map = hazelcastInstance.getMap(dataset.getMapName());
mapIterator = map.entrySet().iterator();
}
if (!mapIterator.hasNext()) {
return null;
}
final Map.Entry<String, String> entry = mapIterator.next();
return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build();
}
@PreDestroy
public void release() {
// clean and release any resources
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
}Now, The hazel cast Source is completed. Let’s write a simple unit test to check that it’s working.
Test the source
TCK provide a set of testing api and tools that makes the testing simple and straight forward. So let’s create our first test.
To test our hazelcast Source, we will create an embedded hazelcast instance of only one member, for now, and initialize it with some data. Then we will create a test Job that will read the data from it using the Source that we have just implemented.
So for that, let’s start by adding the the required test maven dependencies to our project.
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.5.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.talend.sdk.component</groupId>
<artifactId>component-runtime-junit</artifactId>
<version>1.1.12</version>
<scope>test</scope>
</dependency>Let’s start initializing a hazelcast test instance. and let’s create a map with some test data.
For that, create the test class HazelcastSourceTest.java in src/test/java folder that you will need to create before.
package org.talend.components.hazelcast;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertEquals;
class HazelcastSourceTest {
private static final String MAP_NAME = "MY-DISTRIBUTED-MAP";
private static HazelcastInstance hazelcastInstance;
@BeforeAll
static void init() {
hazelcastInstance = Hazelcast.newHazelcastInstance();
IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
}
@Test
void initTest() {
IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
assertEquals(4, map.size());
}
@AfterAll
static void shutdown() {
hazelcastInstance.shutdown();
}
}Here we start by creating a hazelcast instance for our test. then we create the MY-DISTRIBUTED-MAP map. The get map will
create the map if it’s not already exists. Then we add some key, values that we will use in our test.
After that we have a simple test that check that the data was correctly initialized. By the end, we shutdown the hazelcast test
instance.
Run the test by execution and check in the logs that a hazelcast cluster of one member is created and that the test is passing.
$ mvn clean testNow, let’s create our test job to test our Source.
To be able to test the component. TCK provides the annotation @WithComponents which enable component testing. So, let’s
start by adding this annotation to our test. The annotation takes the components java package as a value parameter.
package org.talend.components.hazelcast;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.talend.sdk.component.junit5.WithComponents;
import static org.junit.jupiter.api.Assertions.assertEquals;
@WithComponents("org.talend.components.hazelcast")
class HazelcastSourceTest {
private static final String MAP_NAME = "MY-DISTRIBUTED-MAP";
private static HazelcastInstance hazelcastInstance;
@BeforeAll
static void init() {
hazelcastInstance = Hazelcast.newHazelcastInstance();
IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
}
@Test
void initTest() {
IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
assertEquals(4, map.size());
}
@AfterAll
static void shutdown() {
hazelcastInstance.shutdown();
}
}Now let’s create the test job that will configure the hazelcast and link it to an output that will collect the data that will be produced by the source.
package org.talend.components.hazelcast;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.junit.BaseComponentsHandler;
import org.talend.sdk.component.junit5.Injected;
import org.talend.sdk.component.junit5.WithComponents;
import org.talend.sdk.component.runtime.manager.chain.Job;
import java.util.List;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample;
@WithComponents("org.talend.components.hazelcast")
class HazelcastSourceTest {
private static final String MAP_NAME = "MY-DISTRIBUTED-MAP";
private static HazelcastInstance hazelcastInstance;
@Injected
protected BaseComponentsHandler componentsHandler;
@BeforeAll
static void init() {
hazelcastInstance = Hazelcast.newHazelcastInstance();
IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
}
@Test
void initTest() {
IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME);
assertEquals(4, map.size());
}
@Test
void sourceTest() {
final HazelcastDatastore connection = new HazelcastDatastore();
connection.setClusterIpAddress(hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost());
connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName());
connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword());
final HazelcastDataset dataset = new HazelcastDataset();
dataset.setConnection(connection);
dataset.setMapName(MAP_NAME);
final String configUri = configurationByExample().forInstance(dataset).configured().toQueryString();
Job.components()
.component("Input", "Hazelcast://Input?" + configUri)
.component("Output", "test://collector")
.connections()
.from("Input").to("Output")
.build()
.run();
List<Record> data = componentsHandler.getCollectedData(Record.class);
assertEquals(4, data.size());
}
@AfterAll
static void shutdown() {
hazelcastInstance.shutdown();
}
}Note that we have added the componentsHandler attribute which will be injected by TCK to our test. This component handler
gives us access to the collected data.
In sourceTest method we have instantiated the configuration of the source and fill it we the configuration of our hazelcast
test instance created before to let the source connect to it.
The Job API provide a simple way to build a DAG (directed acyclic graph) job using Talend components and then run it on
a specific runner (standalone, beam or spark). in this test we will first start using only the default runner which is the
standalone one.
the configurationByExample() method create the ByExample factory which provide a simple way to convert the configuration
instance to an URI configuration that can be used with the Job API to configure the component correctly.
At the end we run the job and check that the collected data size is equals to the initialized test data.
Execute the unit test and check that it’s passing. So our source is reading the data correctly from hazelcast.
$ mvn clean testBy that, our simple source is completed and tested. In the next section we will implement a the partition mapper for the source which will be responsible of spiting the work (data reading) corresponding to the available cluster members to distribute the work load.
Partition Mapper
The partition mapper will be responsible of calculating the number of Source that can be created and executed in parallel on different available worker in a distributed system. (in hazelcast it will corresponds to the cluster members counts)
So, le’s evolve our test environment to add more hazelcast members and initialize it with more data.
For that, we will need to instantiate more hazelcast instance as every hazelcast instance correspond to one member in a cluster. In our test this can be done as the following:
package org.talend.components.hazelcast;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.junit.BaseComponentsHandler;
import org.talend.sdk.component.junit5.Injected;
import org.talend.sdk.component.junit5.WithComponents;
import org.talend.sdk.component.runtime.manager.chain.Job;
import java.util.List;
import java.util.UUID;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample;
@WithComponents("org.talend.components.hazelcast")
class HazelcastSourceTest {
private static final String MAP_NAME = "MY-DISTRIBUTED-MAP";
private static final int CLUSTER_MEMBERS_COUNT = 2;
private static final int MAX_DATA_COUNT_BY_MEMBER = 50;
private static List<HazelcastInstance> hazelcastInstances;
@Injected
protected BaseComponentsHandler componentsHandler;
@BeforeAll
static void init() {
hazelcastInstances = IntStream.range(0, CLUSTER_MEMBERS_COUNT)
.mapToObj(i -> Hazelcast.newHazelcastInstance())
.collect(Collectors.toList());
//add some data
hazelcastInstances.forEach(hz -> {
final IMap<String, String> map = hz.getMap(MAP_NAME);
IntStream.range(0, MAX_DATA_COUNT_BY_MEMBER)
.forEach(i -> map.put(UUID.randomUUID().toString(), "value " + i));
});
}
@Test
void initTest() {
IMap<String, String> map = hazelcastInstances.get(0).getMap(MAP_NAME);
assertEquals(CLUSTER_MEMBERS_COUNT * MAX_DATA_COUNT_BY_MEMBER, map.size());
}
@Test
void sourceTest() {
final HazelcastDatastore connection = new HazelcastDatastore();
HazelcastInstance hazelcastInstance = hazelcastInstances.get(0);
connection.setClusterIpAddress(
hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost());
connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName());
connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword());
final HazelcastDataset dataset = new HazelcastDataset();
dataset.setConnection(connection);
dataset.setMapName(MAP_NAME);
final String configUri = configurationByExample().forInstance(dataset).configured().toQueryString();
Job.components()
.component("Input", "Hazelcast://Input?" + configUri)
.component("Output", "test://collector")
.connections()
.from("Input")
.to("Output")
.build()
.run();
List<Record> data = componentsHandler.getCollectedData(Record.class);
assertEquals(CLUSTER_MEMBERS_COUNT * MAX_DATA_COUNT_BY_MEMBER, data.size());
}
@AfterAll
static void shutdown() {
hazelcastInstances.forEach(HazelcastInstance::shutdown);
}
}Here we create two hazelcast instance which will create two hazelcast members. So we will get a cluster of two members (nodes) where we can distribute the data. We also added more data to the test map and update the shutdown method and our test.
Now let’s run our test on our multi nodes cluster.
mvn clean testNote that the Source is a simple implementation that don’t distribute the work load and read all the data in a classic way without distributing the read action on different cluster member.
Now that we have our multi members hazelcast cluster, we can start implementing a partition mapper that takes into account the cluster size and the available dataset size to distribute the work on the members efficiently.
So let’s implement the partition mapper class. For that, start creating a class file HazelcastPartitionMapper.java
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.util.List;
import java.util.UUID;
import static java.util.Collections.singletonList;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private final RecordBuilderFactory recordBuilderFactory;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName()+"-"+ UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Assessor
public long estimateSize() {
return 0;
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
return null;
}
@Emitter
public HazelcastSource createSource() {
return null;
}
@PreDestroy
public void release() {
if(hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
}When introducing a partition mapper with a Source. The partition mapper will be responsible of parameter injection and source instance creation. This way we move all the attribute initialization from the source to the partition mapper class.
in the configuration we also set an instance name to make it easy to find the client instance in logs and while debugging. We also set the instance class loader to be the tccl.
The partition mapper class is composed of :
-
constructor: responsible of configuration and services injection -
Assessor: method annotated with Assessor is responsible of the dataset size estimation. the estimated dataset size is used by the underlying runner to calculate the optimal bundle size to ditribute the work load efficiently. -
Split: method annotated with Split is responsible of the calculation and the creation of partition mapper instance based on the requested bundle size by the underlying runner.it will create as much partition as possible to handle the work load according to the requested bundle size and the dataset size in a way that bundles can be palatalized efficiently on different available worker (members in hazelcast) -
Emitter: method annotated by Emitter is responsible of the creation of the source instance with an adapted configuration that will let the source to be able of the bundle size to handle the records amount that it will produce. and the required services In other words, it will adapt the configuration to let the source read only the requested bundle of data. The source will need to control the bundle that will be read. Think of it like a pagination pattern where every source instance will read only one page.
Let’s implement the Assessor method
Assessor
The assessor method will need to calculate the memory size of every member on the cluster. for that we will need to submit the some calculation task to the members. for that we will nead a serializable task that is aware of the hazelcast instance
Let’s create our serializable task first.
package org.talend.components.hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.HazelcastInstanceAware;
import java.io.Serializable;
import java.util.concurrent.Callable;
public abstract class SerializableTask<T> implements Callable<T>, Serializable, HazelcastInstanceAware {
protected transient HazelcastInstance localInstance;
@Override
public void setHazelcastInstance(final HazelcastInstance hazelcastInstance) {
localInstance = hazelcastInstance;
}
}We will use this class to submit any task to hazelcast cluster. Now, let’s use it to estimate the dataset size in the assessor method.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IExecutorService;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import static java.util.Collections.singletonList;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private final RecordBuilderFactory recordBuilderFactory;
private transient IExecutorService executorService;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName()+"-"+ UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Assessor
public long estimateSize() {
return getExecutorService().submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
}).values().stream().mapToLong(feature -> {
try {
return feature.get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}).sum();
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
return null;
}
@Emitter
public HazelcastSource createSource() {
return null;
}
@PreDestroy
public void release() {
if(hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
private IExecutorService getExecutorService() {
return executorService == null ?
executorService = hazelcastInstance.getExecutorService("talend-executor-service") :
executorService;
}
}In the Assessor method we calculate the memory size that our map occupies on all the members.
In hazelcast, to distribute the a task to all the members we use an execution service which we initialize in getExecutorService()
method. So we request the size of the map on every available member and then we sum the result to get the total size of the
map in the distributed cluster.
Now, let’s implement the
Splitmethod.
Split
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IExecutorService;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import static java.util.Collections.singletonList;
import static java.util.Collections.synchronizedMap;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.toMap;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private final RecordBuilderFactory recordBuilderFactory;
private transient IExecutorService executorService;
private List<String> members;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
private HazelcastPartitionMapper(final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = membersUUID;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Assessor
public long estimateSize() {
return executorService.submitToAllMembers(
() -> hazelcastInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost())
.values()
.stream()
.mapToLong(feature -> {
try {
return feature.get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
})
.sum();
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
final Map<String, Long> heapSizeByMember =
getExecutorService().submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
}).entrySet().stream().map(heapSizeMember -> {
try {
return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(),
heapSizeMember.getValue().get());
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}).collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue));
final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream()
.map(e -> combineMembers(e, bundleSize, heapSizeByMember))
.filter(Objects::nonNull)
.map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m))
.collect(toList());
if (partitions.isEmpty()) {
List<String> allMembers =
hazelcastInstance.getCluster().getMembers().stream().map(Member::getUuid).collect(toList());
partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers));
}
return partitions;
}
private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) {
if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) {
return null;
}
final List<String> combined = new ArrayList<>();
long size = sizeByMember.remove(current);
combined.add(current);
for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Long> entry = it.next();
if (size + entry.getValue() <= bundleSize) {
combined.add(entry.getKey());
size += entry.getValue();
it.remove();
}
}
return combined;
}
@Emitter
public HazelcastSource createSource() {
return null;
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
private IExecutorService getExecutorService() {
return executorService == null ?
executorService = hazelcastInstance.getExecutorService("talend-executor-service") :
executorService;
}
}the split method calculate the heap size of our map on every member of the cluster. Then, it calculate how much members, a source can handle. As the only thing that we can distribute with a configuration like this is to split the reading task from the different members.
So if a member contains less data than the requested bundle size we check if we can combine it with the data from an other member where the combination of the two members data size is less or equals to the requested bundle size.
Read the code carefully to fully understand the logic implemented here.
Now, that we have finished the implementation of the split, let adapt the source to take into account the split. The source will get the list of members from where it will read data.
Source
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import static java.util.Collections.singletonList;
import static java.util.stream.Collectors.toMap;
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
private transient HazelcastInstance hazelcastInstance;
private final List<String> members;
private transient Iterator<Map.Entry<String, String>> mapIterator;
private final RecordBuilderFactory recordBuilderFactory;
private transient Iterator<Map.Entry<Member, Future<Map<String, String>>>> dataByMember;
public HazelcastSource(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory,
final List<String> members) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = members;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Producer
public Record next() {
if (dataByMember == null) {
dataByMember = hazelcastInstance.getExecutorService("talend-source")
.submitToMembers(new SerializableTask<Map<String, String>>() {
@Override
public Map<String, String> call() {
final IMap<String, String> map = localInstance.getMap(dataset.getMapName());
final Set<String> localKeySet = map.localKeySet();
return localKeySet.stream().collect(toMap(k -> k, map::get));
}
}, member -> members.contains(member.getUuid()))
.entrySet()
.iterator();
}
if (mapIterator != null && !mapIterator.hasNext() && !dataByMember.hasNext()) {
return null;
}
if (mapIterator == null || !mapIterator.hasNext()) {
Map.Entry<Member, Future<Map<String, String>>> next = dataByMember.next();
try {
mapIterator = next.getValue().get().entrySet().iterator();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
Map.Entry<String, String> entry = mapIterator.next();
return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build();
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
}In the next method we read the data from the members that we will get from the partition mapper.
In a bigdata runner (like spark) we will get multiple source instance. and every source instance will be responsible of reading data from a specific set of members already calculated by the partition mapper.
Take some time to read the code and to understand what it’s going on and how we iterate on the data member by member.
The data is fetched only when the next method is called. Which let us stream the data from members without loading it
all into the memory.
Now, let’s implement the last method of this component. The method annotated by @Emitter in the HazelcastPartitionMapper
class.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IExecutorService;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import static java.util.Collections.singletonList;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.toMap;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper implements Serializable {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private final RecordBuilderFactory recordBuilderFactory;
private transient IExecutorService executorService;
private List<String> members;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
private HazelcastPartitionMapper(final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = membersUUID;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Assessor
public long estimateSize() {
return getExecutorService().submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
}).values().stream().mapToLong(feature -> {
try {
return feature.get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}).sum();
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
final Map<String, Long> heapSizeByMember =
getExecutorService().submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
}).entrySet().stream().map(heapSizeMember -> {
try {
return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(),
heapSizeMember.getValue().get());
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}).collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue));
final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream()
.map(e -> combineMembers(e, bundleSize, heapSizeByMember))
.filter(Objects::nonNull)
.map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m))
.collect(toList());
if (partitions.isEmpty()) {
List<String> allMembers =
hazelcastInstance.getCluster().getMembers().stream().map(Member::getUuid).collect(toList());
partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers));
}
return partitions;
}
private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) {
if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) {
return null;
}
final List<String> combined = new ArrayList<>();
long size = sizeByMember.remove(current);
combined.add(current);
for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Long> entry = it.next();
if (size + entry.getValue() <= bundleSize) {
combined.add(entry.getKey());
size += entry.getValue();
it.remove();
}
}
return combined;
}
@Emitter
public HazelcastSource createSource() {
return new HazelcastSource(dataset, recordBuilderFactory, members);
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
private IExecutorService getExecutorService() {
return executorService == null ?
executorService = hazelcastInstance.getExecutorService("talend-executor-service") :
executorService;
}
}In the createSource() method we create the source instance and we passe the required services and the selected hazelcast
members to the the source instance.
Now, our component is done. It will be able to read data and distribute the work load upon members in a big data execution engine that will manage the distribution of the work load.
Run the test and check that it’s working.
$ mvn clean testIntroduce TCK service
Let’s refactor the component by introducing a service to make some piece of code reusable and avoid code duplication.
Let’s refactor the hazelcast instance creation in a service as the service executor creation.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IExecutorService;
import org.talend.sdk.component.api.service.Service;
import java.io.Serializable;
import java.util.UUID;
import static java.util.Collections.singletonList;
@Service
public class HazelcastService implements Serializable {
private transient HazelcastInstance hazelcastInstance;
private transient IExecutorService executorService;
public HazelcastInstance getOrCreateIntance(final HazelcastDatastore connection) {
if (hazelcastInstance == null || !hazelcastInstance.getLifecycleService().isRunning()) {
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
return hazelcastInstance;
}
public void shutdownInstance() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
public IExecutorService getExecutorService(final HazelcastDatastore connection) {
return executorService == null ?
executorService = getOrCreateIntance(connection).getExecutorService("talend-executor-service") :
executorService;
}
}This service can be injected to the partition mapper and reused from there. so let’s do that.
package org.talend.components.hazelcast;
import com.hazelcast.core.IExecutorService;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.concurrent.ExecutionException;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.toMap;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper implements Serializable {
private final HazelcastDataset dataset;
private final RecordBuilderFactory recordBuilderFactory;
private transient IExecutorService executorService;
private List<String> members;
private final HazelcastService hazelcastService;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory, final HazelcastService hazelcastService) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.hazelcastService = hazelcastService;
}
private HazelcastPartitionMapper(final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID,
final HazelcastService hazelcastService) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.hazelcastService = hazelcastService;
this.members = membersUUID;
}
@PostConstruct
public void init() {
// We initialize the hazelcast instance only on it first usage now
}
@Assessor
public long estimateSize() {
return hazelcastService.getExecutorService(dataset.getConnection())
.submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
})
.values()
.stream()
.mapToLong(feature -> {
try {
return feature.get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
})
.sum();
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
final Map<String, Long> heapSizeByMember = hazelcastService.getExecutorService(dataset.getConnection())
.submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
})
.entrySet()
.stream()
.map(heapSizeMember -> {
try {
return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(),
heapSizeMember.getValue().get());
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
})
.collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue));
final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream()
.map(e -> combineMembers(e, bundleSize, heapSizeByMember))
.filter(Objects::nonNull)
.map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m, hazelcastService))
.collect(toList());
if (partitions.isEmpty()) {
List<String> allMembers = hazelcastService.getOrCreateIntance(dataset.getConnection())
.getCluster()
.getMembers()
.stream()
.map(Member::getUuid)
.collect(toList());
partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers, hazelcastService));
}
return partitions;
}
private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) {
if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) {
return null;
}
final List<String> combined = new ArrayList<>();
long size = sizeByMember.remove(current);
combined.add(current);
for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Long> entry = it.next();
if (size + entry.getValue() <= bundleSize) {
combined.add(entry.getKey());
size += entry.getValue();
it.remove();
}
}
return combined;
}
@Emitter
public HazelcastSource createSource() {
return new HazelcastSource(dataset, recordBuilderFactory, members, hazelcastService);
}
@PreDestroy
public void release() {
hazelcastService.shutdownInstance();
}
}And let’s adapt the Source class to reuse the service.
package org.talend.components.hazelcast;
import com.hazelcast.core.IMap;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import static java.util.stream.Collectors.toMap;
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
private final List<String> members;
private transient Iterator<Map.Entry<String, String>> mapIterator;
private final RecordBuilderFactory recordBuilderFactory;
private transient Iterator<Map.Entry<Member, Future<Map<String, String>>>> dataByMember;
private final HazelcastService hazelcastService;
public HazelcastSource(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory,
final List<String> members, final HazelcastService hazelcastService) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = members;
this.hazelcastService = hazelcastService;
}
@PostConstruct
public void init() {
// We initialize the hazelcast instance only on it first usage now
}
@Producer
public Record next() {
if (dataByMember == null) {
dataByMember = hazelcastService.getOrCreateIntance(dataset.getConnection())
.getExecutorService("talend-source")
.submitToMembers(new SerializableTask<Map<String, String>>() {
@Override
public Map<String, String> call() {
final IMap<String, String> map = localInstance.getMap(dataset.getMapName());
final Set<String> localKeySet = map.localKeySet();
return localKeySet.stream().collect(toMap(k -> k, map::get));
}
}, member -> members.contains(member.getUuid()))
.entrySet()
.iterator();
}
if (mapIterator != null && !mapIterator.hasNext() && !dataByMember.hasNext()) {
return null;
}
if (mapIterator == null || !mapIterator.hasNext()) {
Map.Entry<Member, Future<Map<String, String>>> next = dataByMember.next();
try {
mapIterator = next.getValue().get().entrySet().iterator();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
Map.Entry<String, String> entry = mapIterator.next();
return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build();
}
@PreDestroy
public void release() {
hazelcastService.shutdownInstance();
}
}rerun the test to ensure everything still working correctly.
That’s all for this tutorial. Now you should be able to create any input component for any system ;)