This tutorial walks you through the creation, from scratch, of a complete Talend input component for Hazelcast using the Talend Component Kit (TCK) framework.
Hazelcast is an in-memory distributed system that can store data, which makes it a good example of input component for distributed systems. This is enough for you to get started with this tutorial, but you can find more information about it here: hazelcast.org/.
Creating the project
A TCK project is a simple Java project with specific configurations and dependencies. You can choose your preferred build tool from Maven or Gradle as TCK supports both. In this tutorial, Maven is used.
The first step consists in generating the project structure using Talend Starter Toolkit .
-
Go to starter-toolkit.talend.io/ and fill in the project information as shown in the screenshots below, then click Finish and Download as ZIP.
image::tutorial_hazelcast_generateproject_1.png[]
image::tutorial_hazelcast_generateproject_2.png[] -
Extract the ZIP file into your workspace and import it to your preferred IDE. This tutorial uses Intellij IDE, but you can use Eclipse or any other IDE that you are comfortable with.
You can use the Starter Toolkit to define the full configuration of the component, but in this tutorial some parts are configured manually to explain key concepts of TCK. The generated
pom.xmlfile of the project looks as follows:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.talend.components.hazelcast</groupId> <artifactId>hazelcast-component</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>Component Hazelcast</name> <description>A generated component project</description> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!-- Set it to true if you want the documentation to be rendered as HTML and PDF You can also use it in the command line: -Dtalend.documentation.htmlAndPdf=true --> <talend.documentation.htmlAndPdf>false</talend.documentation.htmlAndPdf> <!-- if you want to deploy into the Studio you can use the related goal: mvn package talend-component:deploy-in-studio -Dtalend.component.studioHome=/path/to/studio TIP: it is recommended to set this property into your settings.xml in an active by default profile. --> <talend.component.studioHome /> </properties> <dependencies> <dependency> <groupId>org.talend.sdk.component</groupId> <artifactId>component-api</artifactId> <version>1.1.12</version> <scope>provided</scope> </dependency> </dependencies> <build> <extensions> <extension> <groupId>org.talend.sdk.component</groupId> <artifactId>talend-component-maven-plugin</artifactId> <version>1.1.12</version> </extension> </extensions> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>1.8</source> <target>1.8</target> <forceJavacCompilerUse>true</forceJavacCompilerUse> <compilerId>javac</compilerId> <fork>true</fork> <compilerArgs> <arg>-parameters</arg> </compilerArgs> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0-M3</version> <configuration> <trimStackTrace>false</trimStackTrace> <runOrder>alphabetical</runOrder> </configuration> </plugin> </plugins> </build> </project> -
Change the
nametag to a more relevant value, for example: <name>Component Hazelcast</name>.-
The
component-apidependency provides the necessary API to develop the components. -
talend-component-maven-pluginprovides build and validation tools for the component development.The Java compiler also needs a Talend specific configuration for the components to work correctly. The most important is the -parameters option that preserves the parameter names needed for introspection features that TCK relies on.
-
-
Download the mvn dependencies declared in the
pom.xmlfile:$ mvn clean compileYou should get a
BUILD SUCCESSat this point:[INFO] Scanning for projects... [INFO] [INFO] -----< org.talend.components.hazelcast:talend-component-hazelcast >----- [INFO] Building Component :: Hazelcast 1.0.0-SNAPSHOT [INFO] --------------------------------[ jar ]--------------------------------- [INFO] ... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 1.311 s [INFO] Finished at: 2019-09-03T11:42:41+02:00 [INFO] ------------------------------------------------------------------------ -
Create the project structure:
$ mkdir -p src/main/java $ mkdir -p src/main/resources -
Create the component Java packages.
Packages are mandatory in the component model and you cannot use the default one (no package). It is recommended to create a unique package per component to be able to reuse it as dependency in other components, for example to guarantee isolation while writing unit tests. $ mkdir -p src/main/java/org/talend/components/hazelcast $ mkdir -p src/main/resources/org/talend/components/hazelcast
The project is now correctly set up. The next steps consist in registering the component family and setting up some properties.
Registering the Hazelcast components family
Registering every component family allows the component server to properly load the components and to ensure they are available in Talend Studio.
Creating the package-info.java file
The family registration happens via a package-info.java file that you have to create.
Move to the src/main/java/org/talend/components/hazelcast package and create a package-info.java file:
@Components(family = "Hazelcast", categories = "Databases")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
package org.talend.components.hazelcast;
import org.talend.sdk.component.api.component.Components;
import org.talend.sdk.component.api.component.Icon;-
@Components: Declares the family name and the categories to which the component belongs.
-
@Icon: Defines the component family icon. This icon is visible in the Studio metadata tree.
Creating the internationalization file
Talend Component Kit supports internationalization (i18n) via Java properties files. Using these files, you can customize and translate the display name of properties such as the name of a component family or, as shown later in this tutorial, labels displayed in the component configuration.
Go to src/main/resources/org/talend/components/hazelcast and create an i18n Messages.properties file as below:
# An i18n name for the component family
Hazelcast._displayName=HazelcastProviding the family icon
You can define the component family icon in the package-info.java file. The icon image must exist in the resources/icons folder.
TCK supports both SVG and PNG formats for the icons.
-
Create the
iconsfolder and add an icon image for the Hazelcast family.$ mkdir -p /src/main/resources/iconsThis tutorial uses the Hazelcast icon from the official GitHub repository that you can get from: avatars3.githubusercontent.com/u/1453152?s=200&v=4
-
Download the image and rename it to
Hazelcast_icon32.png. The name syntax is important and should match<Icon id from the package-info>_icon.32.png.
The component registration is now complete. The next step consists in defining the component configuration.
Defining the Hazelcast component configuration
All Input and Output (I/O) components follow a predefined model of configuration. The configuration requires two parts:
-
Datastore: Defines all properties that let the component connect to the targeted system.
-
Dataset: Defines the data to be read or written from/to the targeted system.
Datastore
Connecting to the Hazelcast cluster requires the IP address, group name and password of the targeted cluster.
In the component, the datastore is represented by a simple POJO.
-
Create a
HazelcastDatastore.javaclass file in thesrc/main/java/org/talend/components/hazelcastfolder.package org.talend.components.hazelcast; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.configuration.constraint.Required; import org.talend.sdk.component.api.configuration.type.DataStore; import org.talend.sdk.component.api.configuration.ui.layout.GridLayout; import org.talend.sdk.component.api.configuration.ui.widget.Credential; import org.talend.sdk.component.api.meta.Documentation; import java.io.Serializable; @GridLayout({ (1) @GridLayout.Row("clusterIpAddress"), @GridLayout.Row({"groupName", "password"}) }) @DataStore("HazelcastDatastore") (2) @Documentation("Hazelcast Datastore configuration") (3) public class HazelcastDatastore implements Serializable { @Option (4) @Required (5) @Documentation("The hazelcast cluster ip address") private String clusterIpAddress; @Option @Documentation("cluster group name") private String groupName; @Option @Credential (6) @Documentation("cluster password") private String password; // Getters & Setters omitted for simplicity // You need to generate them }1 @GridLayout: define the UI layout of this configuration in a grid manner.2 @DataStore: mark this POJO as being a data store with the idHazelcastDatastorethat can be used to reference the datastore in the i18n files or some services3 @Documentation: document classes and properties. then TCK rely on those metadata to generate a documentation for the component.4 @Option: mark class’s attributes as being a configuration entry.5 @Required: mark a configuration as being required.6 @Credential: mark an Option as being a sensible data that need to be encrypted before it’s stored. -
Define the i18n properties of the datastore. In the
Messages.propertiesfile let add the following lines:#datastore Hazelcast.datastore.HazelcastDatastore._displayName=Hazelcast Connection HazelcastDatastore.clusterIpAddress._displayName=Cluster ip address HazelcastDatastore.groupName._displayName=Group Name HazelcastDatastore.password._displayName=Password
The Hazelcast datastore is now defined.
Dataset
Hazelcast includes different types of datastores. You can manipulate maps, lists, sets, caches, locks, queues, topics and so on.
This tutorial focuses on maps but still applies to the other data structures.
Reading/writing from a map requires the map name.
-
Create the dataset class by creating a
HazelcastDataset.javafile insrc/main/java/org/talend/components/hazelcast.package org.talend.components.hazelcast; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.configuration.type.DataSet; import org.talend.sdk.component.api.configuration.ui.layout.GridLayout; import org.talend.sdk.component.api.meta.Documentation; import java.io.Serializable; @GridLayout({ @GridLayout.Row("connection"), @GridLayout.Row("mapName") }) @DataSet("HazelcastDataset") @Documentation("Hazelcast dataset") public class HazelcastDataset implements Serializable { @Option @Documentation("Hazelcast connection") private HazelcastDatastore connection; @Option @Documentation("Hazelcast map name") private String mapName; // Getters & Setters omitted for simplicity // You need to generate them }The
@Datasetannotation marks the class as a dataset. Note that it also references a datastore, as required by the components model. -
Just how it was done for the datastore, define the i18n properties of the dataset. To do that, add the following lines to the
Messages.propertiesfile.#dataset Hazelcast.dataset.HazelcastDataset._displayName=Hazelcast Map HazelcastDataset.connection._displayName=Connection HazelcastDataset.mapName._displayName=Map Name
The component configuration is now ready. The next step consists in creating the Source that will read the data from the Hazelcast map.
Source
The Source is the class responsible for reading the data from the configured dataset.
A source gets the configuration instance injected by TCK at runtime and uses it to connect to the targeted system and read the data.
-
Create a new class as follows.
package org.talend.components.hazelcast; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.IOException; import java.io.Serializable; @Version @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") (1) @Emitter(name = "Input") (2) @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration) { this.dataset = configuration; } @PostConstruct public void init() throws IOException { //Here we can init connections } @Producer public Record next() { // provide a record every time it is called. Returns null if there is no more data return null; } @PreDestroy public void release() { // clean and release any resources } }1 The Iconannotation defines the icon of the component. Here, it uses the same icon as the family icon but you can use a different one.2 The class is annotated with @Emitter. It marks this class as being a source that will produce records.
The constructor of the source class lets TCK inject the required configuration to the source. We can also inject some common services provided by TCK or other services that we can define in the component. We will see the service part later in this tutorial.3 The method annotated with @PostConstructprepares resources or opens a connection, for example.4 The method annotated with @Producerretrieves the next record if any. The method will returnnullif no more record can be read.5 The method annotated with @PreDestroycleans any resource that was used or opened in the Source. -
The source also needs i18n properties to provide a readable display name. Add the following line to the
Messages.propertiesfile.#Source Hazelcast.Input._displayName=Input -
At this point, it is already possible to see the result in the Talend Component Web Tester to check how the configuration looks like and validate the layout visually. To do that, execute the following command in the project folder.
$ mvn clean install talend-component:webThis command starts the Component Web Tester and deploys the component there.
-
Access localhost:8080/.
[INFO] [INFO] --- talend-component-maven-plugin:1.1.12:web (default-cli) @ talend-component-hazelcast --- [16:46:52.361][INFO ][.WebServer_8080][oyote.http11.Http11NioProtocol] Initializing ProtocolHandler ["http-nio-8080"] [16:46:52.372][INFO ][.WebServer_8080][.catalina.core.StandardService] Starting service [Tomcat] [16:46:52.372][INFO ][.WebServer_8080][e.catalina.core.StandardEngine] Starting Servlet engine: [Apache Tomcat/9.0.22] [16:46:52.378][INFO ][.WebServer_8080][oyote.http11.Http11NioProtocol] Starting ProtocolHandler ["http-nio-8080"] [16:46:52.390][INFO ][.WebServer_8080][g.apache.meecrowave.Meecrowave] --------------- http://localhost:8080 ... [INFO] You can now access the UI at http://localhost:8080 [INFO] Enter 'exit' to quit [INFO] Initializing class org.talend.sdk.component.server.front.ComponentResourceImpl
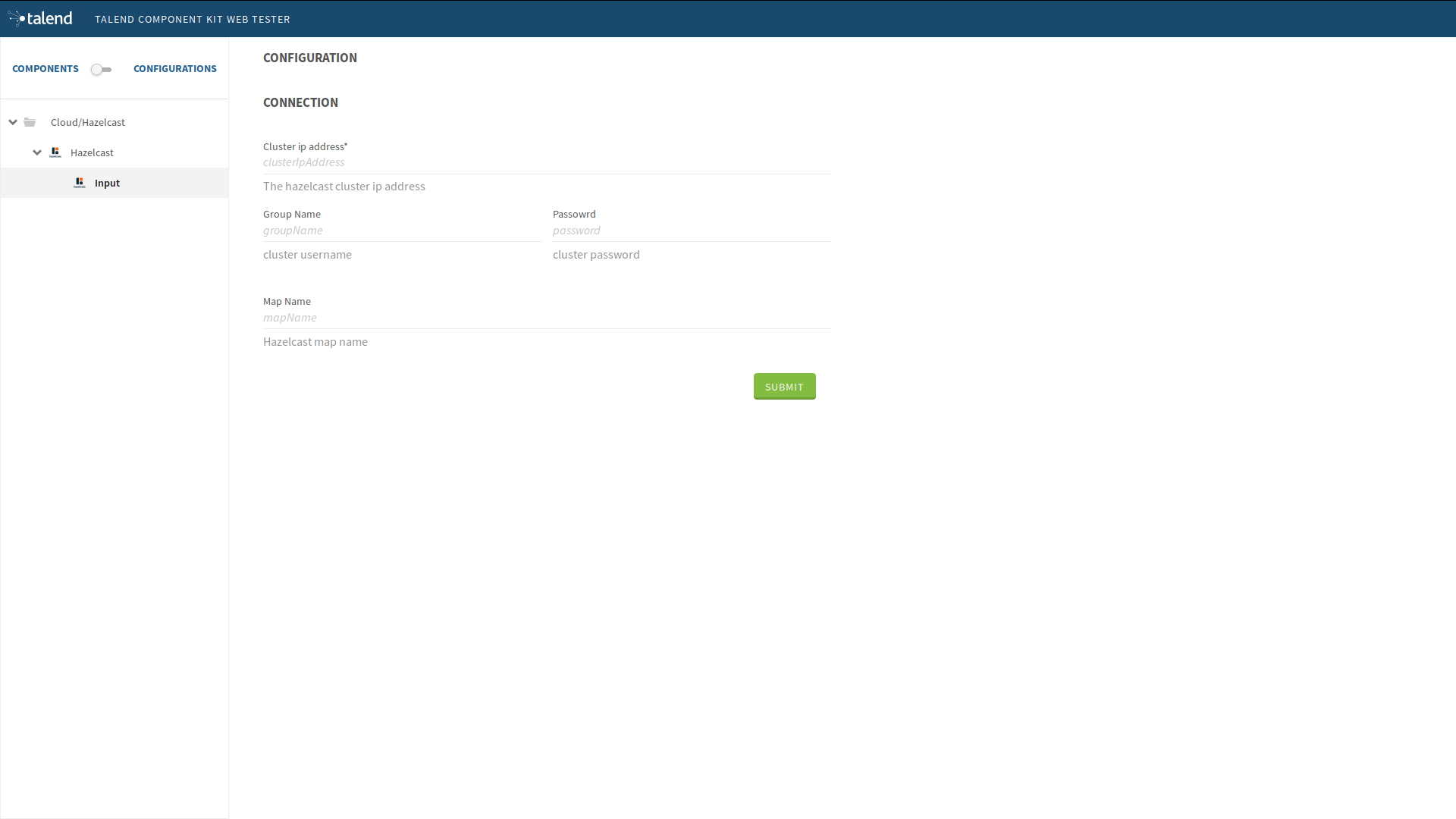
The source is set up. It is now time to start creating some Hazelcast specific code to connect to a cluster and read values for a map.
Source implementation for Hazelcast
-
Add the
hazelcast-clientMaven dependency to thepom.xmlof the project, in thedependenciesnode.<dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast-client</artifactId> <version>3.12.2</version> </dependency> -
Add a Hazelcast instance to the
@PostConstructmethod.-
Declare a
HazelcastInstanceattribute in the source class.Any non-serializable attribute needs to be marked as transient to avoid serialization issues. -
Implement the post construct method.
package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import static java.util.Collections.singletonList; @Version @Emitter(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration) { this.dataset = configuration; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Producer public Record next() { // Provides a record every time it is called. Returns null if there is no more data return null; } @PreDestroy public void release() { // Cleans and releases any resource } }The component configuration is mapped to the Hazelcast client configuration to create a Hazelcast instance. This instance will be used later to get the map from its name and read the map data. Only the required configuration in the component is exposed to keep the code as simple as possible.
-
-
Implement the code responsible for reading the data from the Hazelcast map through the
Producermethod.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.Iterator; import java.util.Map; import static java.util.Collections.singletonList; @Version @Emitter(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private transient Iterator<Map.Entry<String, String>> mapIterator; private final RecordBuilderFactory recordBuilderFactory; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Producer public Record next() { // Provides a record every time it is called. Returns null if there is no more data if (mapIterator == null) { // Gets the Distributed Map from Cluster. IMap<String, String> map = hazelcastInstance.getMap(dataset.getMapName()); mapIterator = map.entrySet().iterator(); } if (!mapIterator.hasNext()) { return null; } final Map.Entry<String, String> entry = mapIterator.next(); return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build(); } @PreDestroy public void release() { // Cleans and releases any resource } }The
Producerimplements the following logic:-
Check if the map iterator is already initialized. If not, get the map from its name and initialize the map iterator. This is done in the
@Producermethod to ensure the map is initialized only if thenext()method is called (lazy initialization). It also avoids the map initialization in thePostConstructmethod as the Hazelcast map is not serializable.All the objects initialized in the PostConstructmethod need to be serializable as the source can be serialized and sent to another worker in a distributed cluster. -
From the map, create an iterator on the map keys that will read from the map.
-
Transform every key/value pair into a Talend Record with a "key, value" object on every call to
next().The RecordBuilderFactoryclass used above is a built-in service in TCK injected via the Source constructor. This service is a factory to create Talend Records. -
Now, the
next()method will produce a Record every time it is called. The method will return "null" if there is no more data in the map.
-
-
Implement the
@PreDestroyannotated method, responsible for releasing all resources used by the Source. The method needs to shut the Hazelcast client instance down to release any connection between the component and the Hazelcast cluster.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.Iterator; import java.util.Map; import static java.util.Collections.singletonList; @Version @Emitter(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private transient Iterator<Map.Entry<String, String>> mapIterator; private final RecordBuilderFactory recordBuilderFactory; public HazelcastSource(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Producer public Record next() { // Provides a record every time it is called. Returns null if there is no more data if (mapIterator == null) { // Get the Distributed Map from Cluster. IMap<String, String> map = hazelcastInstance.getMap(dataset.getMapName()); mapIterator = map.entrySet().iterator(); } if (!mapIterator.hasNext()) { return null; } final Map.Entry<String, String> entry = mapIterator.next(); return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build(); } @PreDestroy public void release() { // Clean and release any resource if (hazelcastInstance != null) { hazelcastInstance.shutdown(); } } }
The Hazelcast Source is completed. The next section shows how to write a simple unit test to check that it works properly.
Testing the Source
TCK provides a set of APIs and tools that makes the testing straightforward.
The test of the Hazelcast Source consists in creating an embedded Hazelcast instance with only one member and initializing it with some data, and then in creating a test Job to read the data from it using the implemented Source.
-
Add the required Maven test dependencies to the project.
<dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter</artifactId> <version>5.5.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.talend.sdk.component</groupId> <artifactId>component-runtime-junit</artifactId> <version>1.1.12</version> <scope>test</scope> </dependency> -
Initialize a Hazelcast test instance and create a map with some test data. To do that, create the
HazelcastSourceTest.javatest class in thesrc/test/javafolder. Create the folder if it does not exist.package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import static org.junit.jupiter.api.Assertions.assertEquals; class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static HazelcastInstance hazelcastInstance; @BeforeAll static void init() { hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); } @Test void initTest() { IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); assertEquals(4, map.size()); } @AfterAll static void shutdown() { hazelcastInstance.shutdown(); } }The above example creates a Hazelcast instance for the test and creates the
MY-DISTRIBUTED-MAPmap. ThegetMapcreates the map if it does not already exist. Some keys and values uses in the test are added. Then, a simple test checks that the data is correctly initialized. Finally, the Hazelcast test instance is shut down. -
Run the test and check in the logs that a Hazelcast cluster of one member has been created and that the test has passed.
$ mvn clean test -
To be able to test components, TCK provides the
@WithComponentsannotation which enables component testing. Add this annotation to the test. The annotation takes the component Java package as a value parameter.package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.talend.sdk.component.junit5.WithComponents; import static org.junit.jupiter.api.Assertions.assertEquals; @WithComponents("org.talend.components.hazelcast") class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static HazelcastInstance hazelcastInstance; @BeforeAll static void init() { hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); } @Test void initTest() { IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); assertEquals(4, map.size()); } @AfterAll static void shutdown() { hazelcastInstance.shutdown(); } } -
Create the test Job that configures the Hazelcast instance and link it to an output that collects the data produced by the Source.
package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.junit.BaseComponentsHandler; import org.talend.sdk.component.junit5.Injected; import org.talend.sdk.component.junit5.WithComponents; import org.talend.sdk.component.runtime.manager.chain.Job; import java.util.List; import static org.junit.jupiter.api.Assertions.assertEquals; import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample; @WithComponents("org.talend.components.hazelcast") class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static HazelcastInstance hazelcastInstance; @Injected protected BaseComponentsHandler componentsHandler; (1) @BeforeAll static void init() { hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); } @Test void initTest() { IMap<String, String> map = hazelcastInstance.getMap(MAP_NAME); assertEquals(4, map.size()); } @Test void sourceTest() { (2) final HazelcastDatastore connection = new HazelcastDatastore(); connection.setClusterIpAddress(hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost()); connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName()); connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword()); final HazelcastDataset dataset = new HazelcastDataset(); dataset.setConnection(connection); dataset.setMapName(MAP_NAME); final String configUri = configurationByExample().forInstance(dataset).configured().toQueryString(); (3) Job.components() .component("Input", "Hazelcast://Input?" + configUri) .component("Output", "test://collector") .connections() .from("Input").to("Output") .build() .run(); List<Record> data = componentsHandler.getCollectedData(Record.class); assertEquals(4, data.size()); (4) } @AfterAll static void shutdown() { hazelcastInstance.shutdown(); } }1 The componentsHandlerattribute is injected to the test by TCK. This component handler gives access to the collected data.2 The sourceTestmethod instantiates the configuration of the Source and fills it with the configuration of the Hazelcast test instance created before to let the Source connect to it.
The Job API provides a simple way to build a DAG (Directed Acyclic Graph) Job using Talend components and then runs it on a specific runner (standalone, Beam or Spark). This test starts using the default runner only, which is the standalone one.3 The configurationByExample()method creates theByExamplefactory. It provides a simple way to convert the configuration instance to an URI configuration used with the Job API to configure the component.4 The job runs and checks that the collected data size is equal to the initialized test data. -
Execute the unit test and check that it passes, meaning that the Source is reading the data correctly from Hazelcast.
$ mvn clean test
The Source is now completed and tested. The next section shows how to implement the Partition Mapper for the Source. In this case, the Partition Mapper will split the work (data reading) between the available cluster members to distribute the workload.
Partition Mapper
The Partition Mapper calculates the number of Sources that can be created and executed in parallel on the available workers of a distributed system. For Hazelcast, it corresponds to the cluster member count.
To fully illustrate this concept, this section also shows how to enhance the test environment to add more Hazelcast cluster members and initialize it with more data.
-
Instantiate more Hazelcast instances, as every Hazelcast instance corresponds to one member in a cluster. In the test, it is reflected as follows:
package org.talend.components.hazelcast; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IMap; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.junit.BaseComponentsHandler; import org.talend.sdk.component.junit5.Injected; import org.talend.sdk.component.junit5.WithComponents; import org.talend.sdk.component.runtime.manager.chain.Job; import java.util.List; import java.util.UUID; import java.util.stream.Collectors; import java.util.stream.IntStream; import static org.junit.jupiter.api.Assertions.assertEquals; import static org.talend.sdk.component.junit.SimpleFactory.configurationByExample; @WithComponents("org.talend.components.hazelcast") class HazelcastSourceTest { private static final String MAP_NAME = "MY-DISTRIBUTED-MAP"; private static final int CLUSTER_MEMBERS_COUNT = 2; private static final int MAX_DATA_COUNT_BY_MEMBER = 50; private static List<HazelcastInstance> hazelcastInstances; @Injected protected BaseComponentsHandler componentsHandler; @BeforeAll static void init() { hazelcastInstances = IntStream.range(0, CLUSTER_MEMBERS_COUNT) .mapToObj(i -> Hazelcast.newHazelcastInstance()) .collect(Collectors.toList()); //add some data hazelcastInstances.forEach(hz -> { final IMap<String, String> map = hz.getMap(MAP_NAME); IntStream.range(0, MAX_DATA_COUNT_BY_MEMBER) .forEach(i -> map.put(UUID.randomUUID().toString(), "value " + i)); }); } @Test void initTest() { IMap<String, String> map = hazelcastInstances.get(0).getMap(MAP_NAME); assertEquals(CLUSTER_MEMBERS_COUNT * MAX_DATA_COUNT_BY_MEMBER, map.size()); } @Test void sourceTest() { final HazelcastDatastore connection = new HazelcastDatastore(); HazelcastInstance hazelcastInstance = hazelcastInstances.get(0); connection.setClusterIpAddress( hazelcastInstance.getCluster().getMembers().iterator().next().getAddress().getHost()); connection.setGroupName(hazelcastInstance.getConfig().getGroupConfig().getName()); connection.setPassword(hazelcastInstance.getConfig().getGroupConfig().getPassword()); final HazelcastDataset dataset = new HazelcastDataset(); dataset.setConnection(connection); dataset.setMapName(MAP_NAME); final String configUri = configurationByExample().forInstance(dataset).configured().toQueryString(); Job.components() .component("Input", "Hazelcast://Input?" + configUri) .component("Output", "test://collector") .connections() .from("Input") .to("Output") .build() .run(); List<Record> data = componentsHandler.getCollectedData(Record.class); assertEquals(CLUSTER_MEMBERS_COUNT * MAX_DATA_COUNT_BY_MEMBER, data.size()); } @AfterAll static void shutdown() { hazelcastInstances.forEach(HazelcastInstance::shutdown); } }The above code sample creates two Hazelcast instances, leading to the creation of two Hazelcast members. Having a cluster of two members (nodes) will allow to distribute the data.
The above code also adds more data to the test map and updates the shutdown method and the test. -
Run the test on the multi-nodes cluster.
mvn clean testThe Source is a simple implementation that does not distribute the workload and reads the data in a classic way, without distributing the read action to different cluster members. -
Start implementing the Partition Mapper class by creating a
HazelcastPartitionMapper.javaclass file.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.util.List; import java.util.UUID; import static java.util.Collections.singletonList; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private final RecordBuilderFactory recordBuilderFactory; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName()+"-"+ UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Assessor public long estimateSize() { return 0; } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { return null; } @Emitter public HazelcastSource createSource() { return null; } @PreDestroy public void release() { if(hazelcastInstance != null) { hazelcastInstance.shutdown(); } } }When coupling a Partition Mapper with a Source, the Partition Mapper becomes responsible for injecting parameters and creating source instances. This way, all the attribute initialization part moves from the Source to the Partition Mapper class.
The configuration also sets an instance name to make it easy to find the client instance in the logs or while debugging.
The Partition Mapper class is composed of the following:
-
constructor: Handles configuration and service injections -
Assessor: This annotation indicates that the method is responsible for assessing the dataset size. The underlying runner uses the estimated dataset size to compute the optimal bundle size to distribute the workload efficiently. -
Split: This annotation indicates that the method is responsible for creating Partition Mapper instances based on the bundle size requested by the underlying runner and the size of the dataset. It creates as much partitions as possible to parallelize and distribute the workload efficiently on the available workers (known as members in the Hazelcast case). -
Emitter: This annotation indicates that the method is responsible for creating the Source instance with an adapted configuration allowing to handle the amount of records it will produce and the required services.
I adapts the configuration to let the Source read only the requested bundle of data.
-
Assessor
The Assessor method computes the memory size of every member of the cluster. Implementing it requires submitting a calculation task to the members through a serializable task that is aware of the Hazelcast instance.
-
Create the serializable task.
package org.talend.components.hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.HazelcastInstanceAware; import java.io.Serializable; import java.util.concurrent.Callable; public abstract class SerializableTask<T> implements Callable<T>, Serializable, HazelcastInstanceAware { protected transient HazelcastInstance localInstance; @Override public void setHazelcastInstance(final HazelcastInstance hazelcastInstance) { localInstance = hazelcastInstance; } }The purpose of this class is to submit any task to the Hazelcast cluster.
-
Use the created task to estimate the dataset size in the
Assessormethod.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IExecutorService; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.util.List; import java.util.UUID; import java.util.concurrent.ExecutionException; import static java.util.Collections.singletonList; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private final RecordBuilderFactory recordBuilderFactory; private transient IExecutorService executorService; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName()+"-"+ UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Assessor public long estimateSize() { return getExecutorService().submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }).values().stream().mapToLong(feature -> { try { return feature.get(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }).sum(); } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { return null; } @Emitter public HazelcastSource createSource() { return null; } @PreDestroy public void release() { if(hazelcastInstance != null) { hazelcastInstance.shutdown(); } } private IExecutorService getExecutorService() { return executorService == null ? executorService = hazelcastInstance.getExecutorService("talend-executor-service") : executorService; } }The
Assessormethod calculates the memory size that the map occupies for all members.
In Hazelcast, distributing a task to all members can be achieved using an execution service initialized in thegetExecutorService()method. The size of the map is requested on every available member. By summing up the results, the total size of the map in the distributed cluster is computed.
Split
The Split method calculates the heap size of the map on every member of the cluster.
Then, it calculates how many members a source can handle.
If a member contains less data than the requested bundle size, the method tries to combine it with another member. That combination can only happen if the combined data size is still less or equal to the requested bundle size.
The following code illustrates the logic described above.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IExecutorService;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.component.Icon;
import org.talend.sdk.component.api.component.Version;
import org.talend.sdk.component.api.configuration.Option;
import org.talend.sdk.component.api.input.Assessor;
import org.talend.sdk.component.api.input.Emitter;
import org.talend.sdk.component.api.input.PartitionMapper;
import org.talend.sdk.component.api.input.PartitionSize;
import org.talend.sdk.component.api.input.Split;
import org.talend.sdk.component.api.meta.Documentation;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import static java.util.Collections.singletonList;
import static java.util.Collections.synchronizedMap;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.toMap;
@Version
@PartitionMapper(name = "Input")
@Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast")
@Documentation("Hazelcast source")
public class HazelcastPartitionMapper {
private final HazelcastDataset dataset;
/**
* Hazelcast instance is a client in a Hazelcast cluster
*/
private transient HazelcastInstance hazelcastInstance;
private final RecordBuilderFactory recordBuilderFactory;
private transient IExecutorService executorService;
private List<String> members;
public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
}
private HazelcastPartitionMapper(final HazelcastDataset configuration,
final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = membersUUID;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Assessor
public long estimateSize() {
return executorService.submitToAllMembers(
() -> hazelcastInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost())
.values()
.stream()
.mapToLong(feature -> {
try {
return feature.get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
})
.sum();
}
@Split
public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) {
final Map<String, Long> heapSizeByMember =
getExecutorService().submitToAllMembers(new SerializableTask<Long>() {
@Override
public Long call() {
return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost();
}
}).entrySet().stream().map(heapSizeMember -> {
try {
return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(),
heapSizeMember.getValue().get());
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}).collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue));
final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream()
.map(e -> combineMembers(e, bundleSize, heapSizeByMember))
.filter(Objects::nonNull)
.map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m))
.collect(toList());
if (partitions.isEmpty()) {
List<String> allMembers =
hazelcastInstance.getCluster().getMembers().stream().map(Member::getUuid).collect(toList());
partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers));
}
return partitions;
}
private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) {
if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) {
return null;
}
final List<String> combined = new ArrayList<>();
long size = sizeByMember.remove(current);
combined.add(current);
for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Long> entry = it.next();
if (size + entry.getValue() <= bundleSize) {
combined.add(entry.getKey());
size += entry.getValue();
it.remove();
}
}
return combined;
}
@Emitter
public HazelcastSource createSource() {
return null;
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
private IExecutorService getExecutorService() {
return executorService == null ?
executorService = hazelcastInstance.getExecutorService("talend-executor-service") :
executorService;
}
}The next step consists in adapting the source to take the Split into account.
Source
The following sample shows how to adapt the Source to the Split carried out previously.
package org.talend.components.hazelcast;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.config.ClientNetworkConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import com.hazelcast.core.Member;
import org.talend.sdk.component.api.input.Producer;
import org.talend.sdk.component.api.record.Record;
import org.talend.sdk.component.api.service.record.RecordBuilderFactory;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.Serializable;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.UUID;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import static java.util.Collections.singletonList;
import static java.util.stream.Collectors.toMap;
public class HazelcastSource implements Serializable {
private final HazelcastDataset dataset;
private transient HazelcastInstance hazelcastInstance;
private final List<String> members;
private transient Iterator<Map.Entry<String, String>> mapIterator;
private final RecordBuilderFactory recordBuilderFactory;
private transient Iterator<Map.Entry<Member, Future<Map<String, String>>>> dataByMember;
public HazelcastSource(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory,
final List<String> members) {
this.dataset = configuration;
this.recordBuilderFactory = recordBuilderFactory;
this.members = members;
}
@PostConstruct
public void init() {
//Here we can init connections
final HazelcastDatastore connection = dataset.getConnection();
final ClientNetworkConfig networkConfig = new ClientNetworkConfig();
networkConfig.setAddresses(singletonList(connection.getClusterIpAddress()));
final ClientConfig config = new ClientConfig();
config.setNetworkConfig(networkConfig);
config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword());
config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString());
config.setClassLoader(Thread.currentThread().getContextClassLoader());
hazelcastInstance = HazelcastClient.newHazelcastClient(config);
}
@Producer
public Record next() {
if (dataByMember == null) {
dataByMember = hazelcastInstance.getExecutorService("talend-source")
.submitToMembers(new SerializableTask<Map<String, String>>() {
@Override
public Map<String, String> call() {
final IMap<String, String> map = localInstance.getMap(dataset.getMapName());
final Set<String> localKeySet = map.localKeySet();
return localKeySet.stream().collect(toMap(k -> k, map::get));
}
}, member -> members.contains(member.getUuid()))
.entrySet()
.iterator();
}
if (mapIterator != null && !mapIterator.hasNext() && !dataByMember.hasNext()) {
return null;
}
if (mapIterator == null || !mapIterator.hasNext()) {
Map.Entry<Member, Future<Map<String, String>>> next = dataByMember.next();
try {
mapIterator = next.getValue().get().entrySet().iterator();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
Map.Entry<String, String> entry = mapIterator.next();
return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build();
}
@PreDestroy
public void release() {
if (hazelcastInstance != null) {
hazelcastInstance.shutdown();
}
}
}The next method reads the data from the members received from the Partition Mapper.
A Big Data runner like Spark will get multiple Source instances. Every source instance will be responsible for reading data from a specific set of members already calculated by the Partition Mapper.
The data is fetched only when the next method is called. This logic allows to stream the data from members without loading it
all into the memory.
Emitter
-
Implement the method annotated with
@Emitterin theHazelcastPartitionMapperclass.package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IExecutorService; import com.hazelcast.core.Member; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.AbstractMap; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Objects; import java.util.UUID; import java.util.concurrent.ExecutionException; import static java.util.Collections.singletonList; import static java.util.stream.Collectors.toList; import static java.util.stream.Collectors.toMap; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper implements Serializable { private final HazelcastDataset dataset; /** * Hazelcast instance is a client in a Hazelcast cluster */ private transient HazelcastInstance hazelcastInstance; private final RecordBuilderFactory recordBuilderFactory; private transient IExecutorService executorService; private List<String> members; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; } private HazelcastPartitionMapper(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.members = membersUUID; } @PostConstruct public void init() { //Here we can init connections final HazelcastDatastore connection = dataset.getConnection(); final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } @Assessor public long estimateSize() { return getExecutorService().submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }).values().stream().mapToLong(feature -> { try { return feature.get(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }).sum(); } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { final Map<String, Long> heapSizeByMember = getExecutorService().submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }).entrySet().stream().map(heapSizeMember -> { try { return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(), heapSizeMember.getValue().get()); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }).collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue)); final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream() .map(e -> combineMembers(e, bundleSize, heapSizeByMember)) .filter(Objects::nonNull) .map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m)) .collect(toList()); if (partitions.isEmpty()) { List<String> allMembers = hazelcastInstance.getCluster().getMembers().stream().map(Member::getUuid).collect(toList()); partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers)); } return partitions; } private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) { if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) { return null; } final List<String> combined = new ArrayList<>(); long size = sizeByMember.remove(current); combined.add(current); for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) { Map.Entry<String, Long> entry = it.next(); if (size + entry.getValue() <= bundleSize) { combined.add(entry.getKey()); size += entry.getValue(); it.remove(); } } return combined; } @Emitter public HazelcastSource createSource() { return new HazelcastSource(dataset, recordBuilderFactory, members); } @PreDestroy public void release() { if (hazelcastInstance != null) { hazelcastInstance.shutdown(); } } private IExecutorService getExecutorService() { return executorService == null ? executorService = hazelcastInstance.getExecutorService("talend-executor-service") : executorService; } }The
createSource()method creates the source instance and passes the required services and the selected Hazelcast members to the source instance. -
Run the test and check that it works as intended.
$ mvn clean testThe component implementation is now done. It is able to read data and to distribute the workload to available members in a Big Data execution environment.
Introducing TCK services
Refactor the component by introducing a service to make some pieces of code reusable and avoid code duplication.
-
Refactor the Hazelcast instance creation into a service.
package org.talend.components.hazelcast; import com.hazelcast.client.HazelcastClient; import com.hazelcast.client.config.ClientConfig; import com.hazelcast.client.config.ClientNetworkConfig; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.IExecutorService; import org.talend.sdk.component.api.service.Service; import java.io.Serializable; import java.util.UUID; import static java.util.Collections.singletonList; @Service public class HazelcastService implements Serializable { private transient HazelcastInstance hazelcastInstance; private transient IExecutorService executorService; public HazelcastInstance getOrCreateIntance(final HazelcastDatastore connection) { if (hazelcastInstance == null || !hazelcastInstance.getLifecycleService().isRunning()) { final ClientNetworkConfig networkConfig = new ClientNetworkConfig(); networkConfig.setAddresses(singletonList(connection.getClusterIpAddress())); final ClientConfig config = new ClientConfig(); config.setNetworkConfig(networkConfig); config.getGroupConfig().setName(connection.getGroupName()).setPassword(connection.getPassword()); config.setInstanceName(getClass().getName() + "-" + UUID.randomUUID().toString()); config.setClassLoader(Thread.currentThread().getContextClassLoader()); hazelcastInstance = HazelcastClient.newHazelcastClient(config); } return hazelcastInstance; } public void shutdownInstance() { if (hazelcastInstance != null) { hazelcastInstance.shutdown(); } } public IExecutorService getExecutorService(final HazelcastDatastore connection) { return executorService == null ? executorService = getOrCreateIntance(connection).getExecutorService("talend-executor-service") : executorService; } } -
Inject this service to the Partition Mapper to reuse it.
package org.talend.components.hazelcast; import com.hazelcast.core.IExecutorService; import com.hazelcast.core.Member; import org.talend.sdk.component.api.component.Icon; import org.talend.sdk.component.api.component.Version; import org.talend.sdk.component.api.configuration.Option; import org.talend.sdk.component.api.input.Assessor; import org.talend.sdk.component.api.input.Emitter; import org.talend.sdk.component.api.input.PartitionMapper; import org.talend.sdk.component.api.input.PartitionSize; import org.talend.sdk.component.api.input.Split; import org.talend.sdk.component.api.meta.Documentation; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.AbstractMap; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Objects; import java.util.concurrent.ExecutionException; import static java.util.stream.Collectors.toList; import static java.util.stream.Collectors.toMap; @Version @PartitionMapper(name = "Input") @Icon(value = Icon.IconType.CUSTOM, custom = "Hazelcast") @Documentation("Hazelcast source") public class HazelcastPartitionMapper implements Serializable { private final HazelcastDataset dataset; private final RecordBuilderFactory recordBuilderFactory; private transient IExecutorService executorService; private List<String> members; private final HazelcastService hazelcastService; public HazelcastPartitionMapper(@Option("configuration") final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, final HazelcastService hazelcastService) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.hazelcastService = hazelcastService; } private HazelcastPartitionMapper(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, List<String> membersUUID, final HazelcastService hazelcastService) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.hazelcastService = hazelcastService; this.members = membersUUID; } @PostConstruct public void init() { // We initialize the hazelcast instance only on it first usage now } @Assessor public long estimateSize() { return hazelcastService.getExecutorService(dataset.getConnection()) .submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }) .values() .stream() .mapToLong(feature -> { try { return feature.get(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }) .sum(); } @Split public List<HazelcastPartitionMapper> split(@PartitionSize final long bundleSize) { final Map<String, Long> heapSizeByMember = hazelcastService.getExecutorService(dataset.getConnection()) .submitToAllMembers(new SerializableTask<Long>() { @Override public Long call() { return localInstance.getMap(dataset.getMapName()).getLocalMapStats().getHeapCost(); } }) .entrySet() .stream() .map(heapSizeMember -> { try { return new AbstractMap.SimpleEntry<>(heapSizeMember.getKey().getUuid(), heapSizeMember.getValue().get()); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } }) .collect(toMap(AbstractMap.SimpleEntry::getKey, AbstractMap.SimpleEntry::getValue)); final List<HazelcastPartitionMapper> partitions = new ArrayList<>(heapSizeByMember.keySet()).stream() .map(e -> combineMembers(e, bundleSize, heapSizeByMember)) .filter(Objects::nonNull) .map(m -> new HazelcastPartitionMapper(dataset, recordBuilderFactory, m, hazelcastService)) .collect(toList()); if (partitions.isEmpty()) { List<String> allMembers = hazelcastService.getOrCreateIntance(dataset.getConnection()) .getCluster() .getMembers() .stream() .map(Member::getUuid) .collect(toList()); partitions.add(new HazelcastPartitionMapper(dataset, recordBuilderFactory, allMembers, hazelcastService)); } return partitions; } private List<String> combineMembers(String current, final long bundleSize, final Map<String, Long> sizeByMember) { if (sizeByMember.isEmpty() || !sizeByMember.containsKey(current)) { return null; } final List<String> combined = new ArrayList<>(); long size = sizeByMember.remove(current); combined.add(current); for (Iterator<Map.Entry<String, Long>> it = sizeByMember.entrySet().iterator(); it.hasNext(); ) { Map.Entry<String, Long> entry = it.next(); if (size + entry.getValue() <= bundleSize) { combined.add(entry.getKey()); size += entry.getValue(); it.remove(); } } return combined; } @Emitter public HazelcastSource createSource() { return new HazelcastSource(dataset, recordBuilderFactory, members, hazelcastService); } @PreDestroy public void release() { hazelcastService.shutdownInstance(); } } -
Adapt the Source class to reuse the service.
package org.talend.components.hazelcast; import com.hazelcast.core.IMap; import com.hazelcast.core.Member; import org.talend.sdk.component.api.input.Producer; import org.talend.sdk.component.api.record.Record; import org.talend.sdk.component.api.service.record.RecordBuilderFactory; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import java.io.Serializable; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Set; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; import static java.util.stream.Collectors.toMap; public class HazelcastSource implements Serializable { private final HazelcastDataset dataset; private final List<String> members; private transient Iterator<Map.Entry<String, String>> mapIterator; private final RecordBuilderFactory recordBuilderFactory; private transient Iterator<Map.Entry<Member, Future<Map<String, String>>>> dataByMember; private final HazelcastService hazelcastService; public HazelcastSource(final HazelcastDataset configuration, final RecordBuilderFactory recordBuilderFactory, final List<String> members, final HazelcastService hazelcastService) { this.dataset = configuration; this.recordBuilderFactory = recordBuilderFactory; this.members = members; this.hazelcastService = hazelcastService; } @PostConstruct public void init() { // We initialize the hazelcast instance only on it first usage now } @Producer public Record next() { if (dataByMember == null) { dataByMember = hazelcastService.getOrCreateIntance(dataset.getConnection()) .getExecutorService("talend-source") .submitToMembers(new SerializableTask<Map<String, String>>() { @Override public Map<String, String> call() { final IMap<String, String> map = localInstance.getMap(dataset.getMapName()); final Set<String> localKeySet = map.localKeySet(); return localKeySet.stream().collect(toMap(k -> k, map::get)); } }, member -> members.contains(member.getUuid())) .entrySet() .iterator(); } if (mapIterator != null && !mapIterator.hasNext() && !dataByMember.hasNext()) { return null; } if (mapIterator == null || !mapIterator.hasNext()) { Map.Entry<Member, Future<Map<String, String>>> next = dataByMember.next(); try { mapIterator = next.getValue().get().entrySet().iterator(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException(e); } } Map.Entry<String, String> entry = mapIterator.next(); return recordBuilderFactory.newRecordBuilder().withString(entry.getKey(), entry.getValue()).build(); } @PreDestroy public void release() { hazelcastService.shutdownInstance(); } } -
Run the test one last time to ensure everything still works as expected.
Thank you for following this tutorial. Use the logic and approach presented here to create any input component for any system.