What is a Talend Component
Basically, a component (or connector) is a functional piece that performs a single operation from a Talend application. For example, tMysqlInput extracts data from a MySQL table, tFilterRow filters data based on a condition.
Physically, a component is a set of files stored within a folder named after the component name. All native components are located in the <Talend Studio installation dir>/plugins/org.talend.designer.components.localprovider_[version]/components directory. Each component is a sub-folder under this directory, the folder name is the component name.
Graphically, a component is an icon that you can drag and drop from the Palette to the workspace.
Technically, a component is a snippet of generated Java code that is part of a Job which is a Java class. A Job is made of one or more components or connectors. The job name will be the class name and each component in a job will be translated to a snippet of generated Java code. The Java code will be compiled automatically when you save the job.
Talend Component Kit helps you creating your own components.
Talend Component Kit methodology
Talend Component Kit is a framework designed to simplify the development of components at two levels:
-
Runtime: Runtime is about injecting the specific component code into a job or pipeline. The framework helps unify as much as possible the code required to run in Data Integration (DI) and BEAM environments.
-
Graphical interface: The framework helps unify the code required to be able to render the component in a browser (web) or in the Eclipse-based Studio (SWT).
Before being able to develop new components, check the prerequisites to make sure that you have all you need to get started.
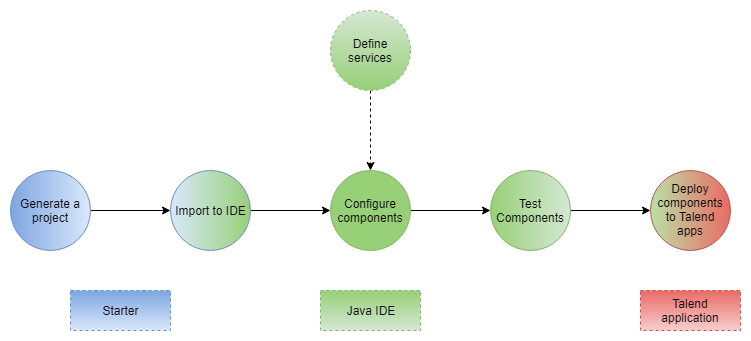
Developing new components using the framework includes:
-
Creating a project using the starter or the Talend IntelliJ plugin. This step allows to build the skeleton of the project. It consists in:
-
Defining the general configuration model for each component in your project
-
Generating and downloading the project archive from the starter
-
Compiling the project
-
-
Importing the compiled project in your IDE. This step is not required if you have generated the project using the IntelliJ plugin.
-
Implementing the components, including:
-
Registering the component by specifying its metadata: family, categories, version, icon, type, and name.
-
Defining the layout and configurable part of the components
-
Defining the partition mapper for Input components
-
Implementing the source logic for Input components
-
Defining the processor for Output components
-
-
Deploying the components to Talend Studio or Cloud applications
Some additional configuration steps can be necessary according to your requirements:
-
Defining services that can be reused in several components
Talend Component Kit Overview
Talend Component Kit is a toolkit based on Java and designed to simplify the development of components at two levels:
-
Runtime: Runtime is about injecting the specific component code into a job or pipeline. The framework helps unify as much as possible the code required to run in Data Integration (DI) and BEAM environments.
-
Graphical interface: The framework helps unify the code required to be able to render the component in a browser (web) or in the Eclipse-based Studio (SWT).
Component API
The component API is declarative (through annotations) to ensure it is:
-
Evolutive. It can get new features without breaking old code.
-
As static as possible.
Evolutive
Because it is fully declarative, any new API can be added iteratively without requiring any change to existing components.
For example, in the case of Beam potential evolution:
@ElementListener
public MyOutput onElement(MyInput data) {
return ...;
}would not be affected by the addition of the new Timer API, which can be used as follows:
@ElementListener
public MyOutput onElement(MyInput data,
@Timer("my-timer") Timer timer) {
return ...;
}Static
UI-friendly
The intent of the framework is to be able to fit in a Java UI as well as in a web UI.
It must be understood as colocalized and remote UI. The goal is to move as much as possible the logic to the UI side for UI-related actions. For example, validating a pattern, a size, and so on, should be done on the client side rather than on the server side. Being static encourages this practice.
Generic and specific
The processor API supports JsonObject as well as any custom model. The goal is to support generic component development that need to access configured "object paths", as well as specific components that rely on a defined path from the input.
A generic component can look like:
@ElementListener
public MyOutput onElement(JsonObject input) {
return ...;
}A specific component can look like (with MyInput a POJO):
@ElementListener
public MyOutput onElement(MyInput input) {
return ...;
}No runtime assumption
By design, the framework must run in DI (plain standalone Java program) and in Beam pipelines.
It is out of scope of the framework to handle the way the runtime serializes - if needed - the data.
For that reason, it is critical not to import serialization constraints to the stack. As an example, this is the reason why JsonObject is not an IndexedRecord from Avro.
Any serialization concern should either be hidden in the framework runtime (outside of the component developer scope) or in the runtime integration with the framework (for example, Beam integration).
In this context, JSON-P can be good compromise because it brings a powerful API with very few constraints.
Isolated
The components must be able to execute even if they have conflicting libraries. For that purpose, classloaders must be isolated. A component defines its dependencies based on a Maven format and is always bound to its own classloader.
REST
Consumable model
The definition payload is as flat as possible and strongly typed to ensure it can be manipulated by consumers. This way, consumers can add or remove fields with simple mapping rules, without any abstract tree handling.
The execution (runtime) configuration is the concatenation of framework metadata (only the version) and a key/value model of the instance of the configuration based on the definition properties paths for the keys. It enables consumers to maintain and work with the keys/values according to their need.
The framework not being responsible for any persistence, it is very important to make sure that consumers can handle it from end to end, with the ability to search for values (update a machine, update a port and so on) and keys (for example, a new encryption rule on key certificate).
Talend Component Kit is a metamodel provider (to build forms) and a runtime execution platform. It takes a configuration instance and uses it volatilely to execute a component logic. This implies it cannot own the data nor define the contract it has for these two endpoints and must let the consumers handle the data lifecycle (creation, encryption, deletion, and so on).
Fixed set of icons
Icons (@Icon) are based on a fixed set. Custom icons can be used but their display cannot be guaranteed. Components can be used in any environment and require a consistent look that cannot be guaranteed outside of the UI itself. Defining keys only is the best way to communicate this information.
| Once you know exactly how you will deploy your component in the Studio, then you can use `@Icon(value = CUSTOM, custom = "…") to use a custom icon file. |
General component execution logic
Each type of component has its own execution logic. The same basic logic is applied to all components of the same type, and is then extended to implement each component specificities. The project generated from the starter already contains the basic logic for each component.
Talend Component Kit framework relies on several primitive components.
All components can use @PostConstruct and @PreDestroy annotations to initialize or release some underlying resource at the beginning and the end of a processing.
In distributed environments, class constructor are called on cluster manager nodes. Methods annotated with @PostConstruct and @PreDestroy are called on worker nodes. Thus, partition plan computation and pipeline tasks are performed on different nodes.
|
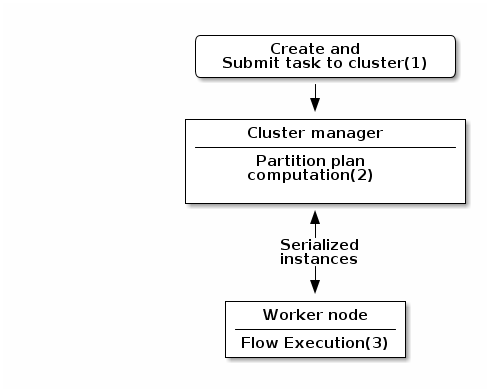
-
The created task is a JAR file containing class information, which describes the pipeline (flow) that should be processed in cluster.
-
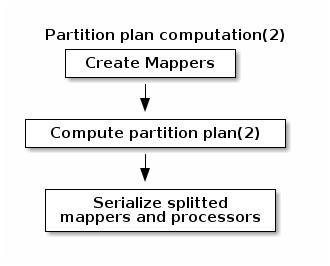
During the partition plan computation step, the pipeline is analyzed and split into stages. The cluster manager node instantiates mappers/processors, gets estimated data size using mappers, and splits created mappers according to the estimated data size.
All instances are then serialized and sent to the worker node. -
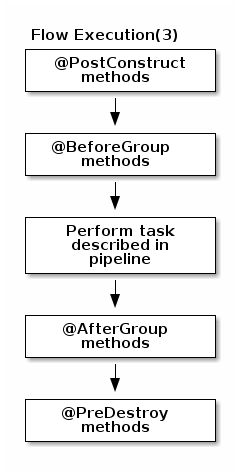
Serialized instances are received and deserialized. Methods annotated with
@PostConstructare called. After that, pipeline execution starts. The@BeforeGroupannotated method of the processor is called before processing the first element in chunk.
After processing the number of records estimated as chunk size, the@AfterGroupannotated method of the processor is called. Chunk size is calculated depending on the environment the pipeline is processed by. Once the pipeline is processed, methods annotated with@PreDestroyare called.
| All the methods managed by the framework must be public. Private methods are ignored. |
| The framework is designed to be as declarative as possible but also to stay extensible by not using fixed interfaces or method signatures. This allows to incrementally add new features of the underlying implementations. |