Processors and output components are the components in charge of reading, processing and transforming data in a Talend job, as well as passing it to its required destination.
Before implementing the component logic and defining its layout and configurable fields, make sure you have specified its basic metadata, as detailed in this document.
Defining a processor
What is a processor
A Processor is a component that converts incoming data to a different model.
A processor must have a method decorated with @ElementListener taking an incoming data and returning the processed data:
@ElementListener
public MyNewData map(final MyData data) {
return ...;
}Processors must be Serializable because they are distributed components.
If you just need to access data on a map-based ruleset, you can use Record or JsonObject as parameter type.
From there, Talend Component Kit wraps the data to allow you to access it as a map. The parameter type is not enforced.
This means that if you know you will get a SuperCustomDto, then you can use it as parameter type. But for generic components that are reusable in any chain, it is highly encouraged to use Record until you have an evaluation language-based processor that has its own way to access components.
For example:
@ElementListener
public MyNewData map(final Record incomingData) {
String name = incomingData.getString("name");
int name = incomingData.getInt("age");
return ...;
}
// equivalent to (using POJO subclassing)
public class Person {
private String age;
private int age;
// getters/setters
}
@ElementListener
public MyNewData map(final Person person) {
String name = person.getName();
int age = person.getAge();
return ...;
}A processor also supports @BeforeGroup and @AfterGroup methods, which must not have any parameter and return void values. Any other result would be ignored.
These methods are used by the runtime to mark a chunk of the data in a way which is estimated good for the execution flow size.
Because the size is estimated, the size of a group can vary. It is even possible to have groups of size 1.
|
It is recommended to batch records, for performance reasons:
@BeforeGroup
public void initBatch() {
// ...
}
@AfterGroup
public void endBatch() {
// ...
}You can optimize the data batch processing by using the maxBatchSize parameter. This parameter is automatically implemented on the component when it is deployed to a Talend application. Only the logic needs to be implemented. You can however customize its value setting in your LocalConfiguration the property _maxBatchSize.value - for the family - or ${component simple class name}._maxBatchSize.value - for a particular component, otherwise its default will be 1000. Learn how to implement chunking/bulking in this document.
Defining multiple outputs
In some cases, you may need to split the output of a processor in two. A common example is to have "main" and "reject" branches where part of the incoming data are passed to a specific bucket to be processed later.
To do that, you can use @Output as replacement of the returned value:
@ElementListener
public void map(final MyData data, @Output final OutputEmitter<MyNewData> output) {
output.emit(createNewData(data));
}Alternatively, you can pass a string that represents the new branch:
@ElementListener
public void map(final MyData data,
@Output final OutputEmitter<MyNewData> main,
@Output("rejected") final OutputEmitter<MyNewDataWithError> rejected) {
if (isRejected(data)) {
rejected.emit(createNewData(data));
} else {
main.emit(createNewData(data));
}
}
// or
@ElementListener
public MyNewData map(final MyData data,
@Output("rejected") final OutputEmitter<MyNewDataWithError> rejected) {
if (isSuspicious(data)) {
rejected.emit(createNewData(data));
return createNewData(data); // in this case the processing continues but notifies another channel
}
return createNewData(data);
}Defining multiple inputs
Having multiple inputs is similar to having multiple outputs, except that an OutputEmitter wrapper is not needed:
@ElementListener
public MyNewData map(@Input final MyData data, @Input("input2") final MyData2 data2) {
return createNewData(data1, data2);
}@Input takes the input name as parameter. If no name is set, it defaults to the "main (default)" input branch. It is recommended to use the default branch when possible and to avoid naming branches according to the component semantic.
Implementing batch processing
Depending on several requirements, including the system capacity and business needs, a processor can process records differently.
For example, for real-time or near-real time processing, it is more interesting to process small batches of data more often. On the other hand, in case of one-time processing, it is more optimal to adapt the way the component handles batches of data according to the system capacity.
By default, the runtime automatically estimates a group size that it considers good, according to the system capacity, to process the data. This group size can sometimes be too big and not optimal for your needs or for your system to handle effectively and correctly.
Users can then customize this size from the component settings in Talend Studio, by specifying a maxBatchSize that adapts the size of each group of data to be processed.
| The estimated group size logic is automatically implemented when a component is deployed to a Talend application. Besides defining the @BeforeGroup and @AfterGroup logic detailed below, no action is required on the implementation side of the component. |
The component batch processes the data as follows:
-
Case 1 - No
maxBatchSizeis specified in the component configuration. The runtime estimates a group size of 4. Records are processed by groups of 4. -
Case 2 - The runtime estimates a group size of 4 but a
maxBatchSizeof 3 is specified in the component configuration. The system adapts the group size to 3. Records are processed by groups of 3.
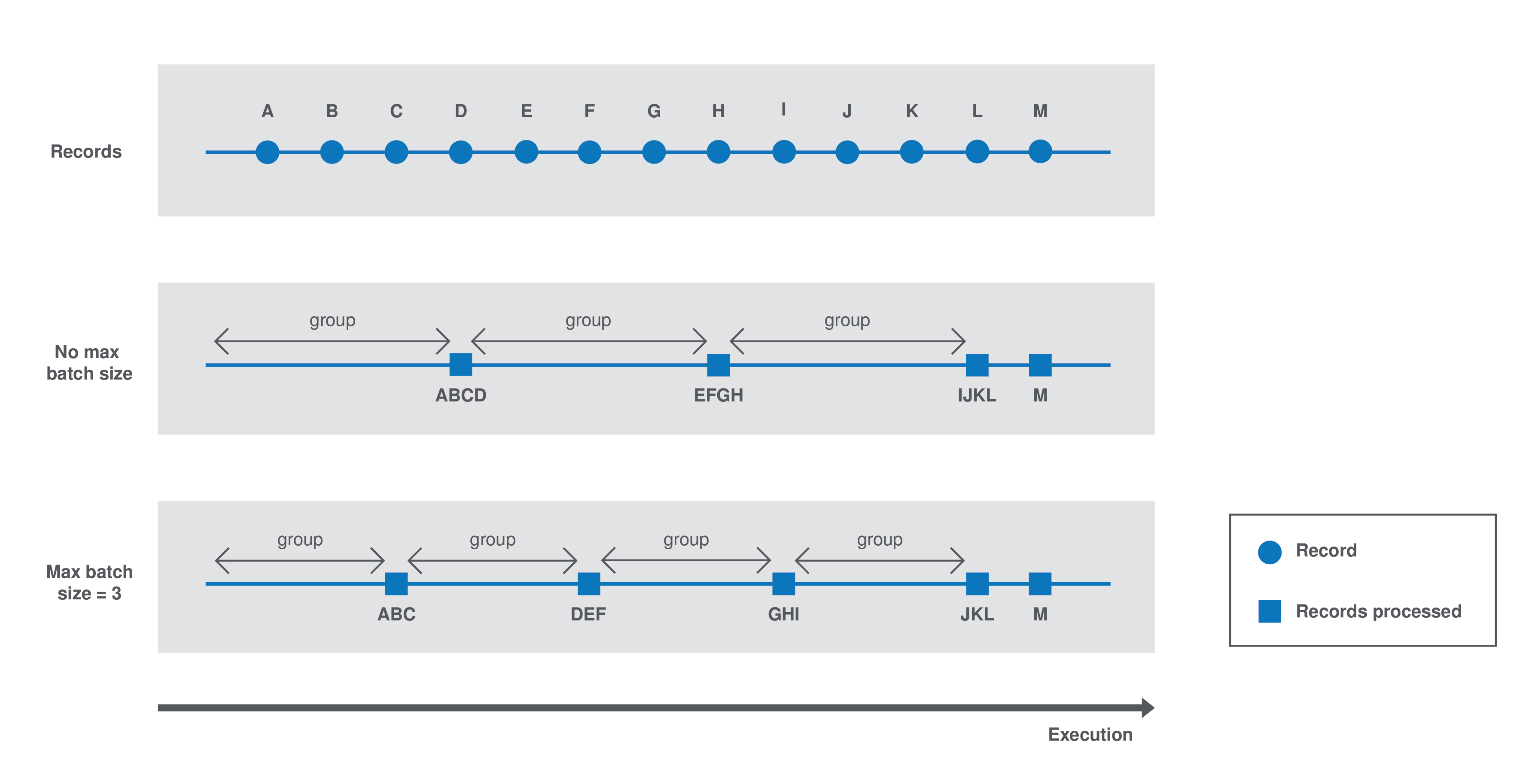
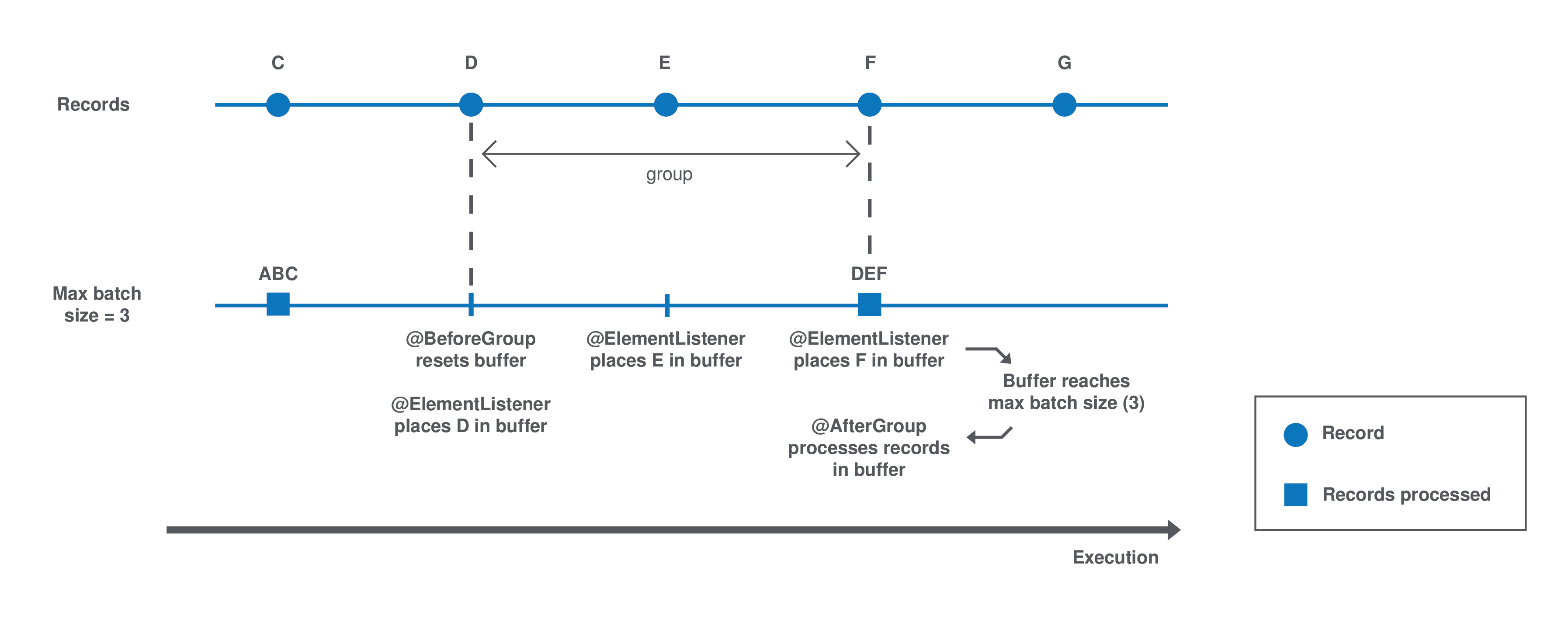
Each group is processed as follows until there is no record left:
-
The
@BeforeGroupmethod resets a record buffer at the beginning of each group. -
The records of the group are assessed one by one and placed in the buffer as follows: The
@ElementListenermethod tests if the buffer size is greater or equal to the definedmaxBatchSize. If it is, the records are processed. If not, then the current record is buffered. -
The previous step happens for all records of the group. Then the
@AfterGroupmethod tests if the buffer is empty.
You can define the following logic in the processor configuration:
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Collection;
import javax.json.JsonObject;
import org.talend.sdk.component.api.processor.AfterGroup;
import org.talend.sdk.component.api.processor.BeforeGroup;
import org.talend.sdk.component.api.processor.ElementListener;
import org.talend.sdk.component.api.processor.Processor;
@Processor(name = "BulkOutputDemo")
public class BulkProcessor implements Serializable {
private Collection<JsonObject> buffer;
@BeforeGroup
public void begin() {
buffer = new ArrayList<>();
}
@ElementListener
public void bufferize(final JsonObject object) {
buffer.add(object);
}
@AfterGroup
public void commit() {
// save buffer records at once (bulk)
}
}You can learn more about processors in this document.
Defining an output
What is an output
An Output is a Processor that does not return any data.
Conceptually, an output is a data listener. It matches the concept of processor. Being the last component of the execution chain or returning no data makes your processor an output component:
@ElementListener
public void store(final MyData data) {
// ...
}